這次的分享,純粹是囫圇吞棗式分享,沒有什麼太難的技術在裡面,只要準備好:
- 原作者的字型檔(或你的手寫字圖檔)。
- 免費的思源黑體(或思源宋體)。
- 整理原作者字型裡有的字。
- 繪圖軟體:非必要。如果需要微調產生出來的圖檔,建議學習一個繪圖軟體,小畫家也可以,不一定需要會編輯向量圖,如果會的話,是有幫助,我用的繪圖軟體是krita。
- FontCreator/FontForge 用來產生字型檔。
然後就可以開始做「筆跡」的學習,進階的用法是倒過來做筆跡的鑑定。
在這裡要推薦一部好看的韓劇,剛好就是在做上面這二件事情,劇名是《啟動了》或《Start-Up》(韓語:스타트업),在台灣及港澳的譯名是《Start-Up:我的新創時代》,為韓國tvN於2020年10月17日起播出的週末連續劇,劇中對 AI 的使用,還有商業模式與簡報的展示有非常深入且專業的見解,最後一集我沒看,因為我個人比較喜歡男配角(金宣虎)。在Netflix 上翻譯是「我的新創時代」。

這次分享,完全不需要寫程式,而且原作者的程式,我也看不懂他在寫什麼,還好,都用作者放上來的範例參數,只帶入我們收集到的字型檔,就完成了。
針對沒有字型檔的情況,也可以手動先收集筆跡圖片,使用手機拍照或掃描手寫字圖片,先把類比轉數位,手動產生訓練所需要的對應用的paired_images ,就可以讓電腦來學習你的筆跡,用AI造字。
認識 Pix2pix
- github: https://github.com/phillipi/pix2pix
- Pix2pix 是一種 Conditional GAN(CGAN),主要用於圖像和圖像之間的映射,或稱為圖像轉譯。
- cGAN(conditonal generative adversial network),可以自動生成符合某些條件或特徵(condition)的圖像。
- 由於 Pix2pix 是圖像的一對一映射,我們在訓練時必須採用成對的(Paired)資料進行訓練。
認識 CycleGAN
github: https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
CycleGAN 是一種將GAN應用於影像風格轉換(Image translation)的非監督式學習演算法。與Pix2Pix不同,CycleGAN的輸入資料不是pair-to-pair的資料,因此CycleGAN演算法可以解決不同domain的成對資料獲取困難的問題。

認識 zi2zi (字到字)
github: https://github.com/kaonashi-tyc/zi2zi
Learning eastern asian language typefaces with GAN. zi2zi(字到字, meaning from character to character) is an application and extension of the recent popular pix2pix model to Chinese characters.
Details could be found in this blog post.
zi2zip 使用上的重點
- 準備訓練所需資料,先把字型變成圖片。
font2img.py - 一張一張分開的圖片檔案,打包成單一個訓練檔案。
package.py - 在 google colab 上訓練
train.py - 推論出原作者未設計過的字,推論滿快的,不一定需要使用GPU的電腦
infer.py
Googe Driver 上的 colab 程式碼:
Step 1: 安裝 Google Driver,
Step 2: 把 github 下載的 zi2zip 程式碼放在 Google Driver 同步的目錄裡.
Step 3: 在 Google Driver 裡新增一個 colab, 增加下面的Code, 並按三角型來執行,掛載 Google Driver 到 colab.
from google.colab import drive
drive.mount('/gdrive')附註: 可以使用下面的範例來測試,有沒有正確地切換到有GPU 的執行環境:
import torch
flag = torch.cuda.is_available()
if flag:
print("CUDA可使用")
else:
print("CUDA不可用")Step 4: 使用下面的指令, 把圖片從 google drive 搬到 VM 電腦硬碟.
%cp -rf '/gdrive/My Drive/Colab Notebooks/zi2zi-pytorch/experiments/data-fontname-regular' /root/附註: 為了避免 Google Driver 搬檔案到 colab 較慢的問題, 可以把 experiment_data_dir 放到 colab 的本地端的儲存空間裡.
Step 4: 使用下面的指令, 開始算圖.
%cd '/gdrive/My Drive/Colab Notebooks/zi2zi-pytorch'
!python train.py --experiment_dir=experiments \
--experiment_data_dir=/root/data \
--gpu_ids=cuda:0 \
--input_nc=1 \
--batch_size=128 \
--epoch=60 \
--schedule=30 \
--sample_steps=2000 \
--checkpoint_steps=500如果是接續前一個 checkpoint 來算, 增加 –resume= 參數.
%cd '/gdrive/My Drive/Colab Notebooks/zi2zi-pytorch'
!python train.py --experiment_dir=experiments \
--experiment_data_dir=/root/data-fontname-regular \
--resume=22 \
--gpu_ids=cuda:0 \
--input_nc=1 \
--batch_size=64 \
--epoch=100 \
--schedule=20 \
--sample_steps=2000 \
--lr=0.0005 \
--checkpoint_steps=100Max造字心得
- 一定要 GPU 或 TPU
我曾在自己的筆電上執行過,由於沒有顯示卡的 GPU 支援,跑了 24小時,連 1/40 都沒完成,要執行深度學習,請一定需要在有 GPU 的電腦或伺服器上執行,才能事半功倍。我是多創了一些 google 帳號,依序在不同的帳號裡透過 google colab 來做訓練。 - 要訓練多久?
有些字型,才訓練了 12 小時,效果就滿好的,一直重覆還有慢慢餵一些自己精選過,想加強訓練的資料之後,效果會再更好,我 fork 出來的專案,有人在 issue 裡問過這一個問題,上一個作者回答說,這個答案很玄,因為連一開始的原作者都沒有一個答案,最後訓練的結果,可能反而效果會更糟,反正有空就丟著給電腦自己去學,總有一個版本效果會好一點。 - 製作出一個字型檔,需要花多久時間?
這個取決於多個因素,如果開發著只有一個人的情況來算,要畫出教育部公告的「常用國字標準字體表」的4808個常用字,每一個字花費5分鐘,一個小時不休息可以畫出20張,一天畫10小時,用 24天就可以達標了。但4808字完全不夠用,大多的字型都是做到 9,000 ~ 12,000 字左右,才會比較不缺字。 - EuphoriaYan/zi2zi-pytorch 與 xuan-li/zi2zi 的差異
這個問題有點難懂,原作者的回答是:
zi2zi-pytorch網絡和原版有變動的是在net_D部分倒數第二層加了個1 x 1的卷積,我測試了一下帶或不帶這個1 x 1卷積,感覺和原版差距不大;所以我就沿用了這個帶1 x 1卷積的,可以加快速度減小模型大小,您可以嘗試去掉這個1 x 1卷積試試。
https://github.com/EuphoriaYan/zi2zi-pytorch/issues/3
還有一個修改點是我們的數據增強方法是基於Font2Font的,和原版不完全一致,您可以查看一下dataset.py里的DatasetFromObj函數,並嘗試修改回原版的數據增強方法。
此外,我們在測試的時候,確實有時候模型會經歷「學習」->「崩潰」->「重新學習」這種情況,所以我們目前工作的時候是先生成一堆sample然後看哪個checkpoint的sample最好。暫時我們沒時間來修復這個問題,生成效果不佳可能和這個問題也有關係,原作者也說了這網絡相當難以訓練(哭)。您可以嘗試在訓練時不只看last_ckpt_sample,也看看別的ckpt的sample,說不定就有哪個ckpt的sample比較好(玄學)
- 免費版colab 的限制
google colab 號稱可以用 12小時,實際上也許 3.5小時,就把 GPU 可以使用的額度用滿了,這時候就把 checkpoint 資料夾裡產生出來的結果,分享給下一個帳號去使用,就可以使用下一個 google 帳號接著做訓練了。參考看看「免費版colab 的限制」:
https://stackoverflow.max-everyday.com/2021/05/free-colab-resources-limit/ - 垃圾進,垃圾出
要拿去訓練的資料,要慎重選擇,這個有另一個講法叫「資料清洗」(Data Cleansing)。我有試過使用 CJK TC(台標體) 的思源黑體,搭配日系的字型,訓練結果大多是很滿意,但由於文字的部件寫法不同,一開始是使用 CJK JP(日本漢字)的思源黑體去推論時,就可能會省下一些後續處理的時間。
例如:日系的草部都是相連的,所以要AI推論出分開的草部的寫法,就不太可能。 - checkpoint 中繼檔案的取得
在 google colab 上訓練的結果,重點就是要取得訓練結果的 checkpoint 檔案,如果資料量有7000筆,使用 batch_size=32 / checkpoint_steps=1000 這2個參數下去訓練,大約每1個小時,可以取得一個 checkpoint 的中續檔案。
如果資料量有7000筆,使用 batch_size=128 / checkpoint_steps=200 這2個參數下去訓練,大約每20分鐘,可以取得一個 checkpoint 的中續檔案。
如果調高 batch_size 為 2倍大,記得降低 checkpoint 的 step 數量為 1/2 ,不然就是 2個小時,才能拿到一個 checkpoint, 萬一在 google colab 的 GUP 的額度用完,卻還沒產生 checkpoint, 那就是是白做工了。調高 batch_size 為 2倍相對 RAM 就會長大為二倍, 如果 GPU 只有 4GB RAM, 以 7千筆資料來說, batch_size 設成 24 大約就只占用 3.5GB, 可以順利的訓練. Google colab 給 GPU RAM 是 15GB, 設成 144, 大約是 14.4GB, 可以增加一點點訓練速度.
建議, 最好讓程式每 10~20分鐘, 產生一個 checkpoint 檔案。把取算完的 checkpoint 複製到其他google 帳號,就可以不中斷地接續訓練模型。
相關文章: 清空 google drive 垃圾桶的內容
https://stackoverflow.max-everyday.com/2025/02/empty-google-driver-trash/ - checkpoint 的計算方式
以下面的執行結果來說:
unpickled total 6644 examples
Epoch: [ 0], [ 0/ 256] time: 3.87, d_loss: 1.44975, g_loss: 20.80817, category_loss: 0.00000, cheat_loss: 0.16015, const_loss: 0.03428, l1_loss: 20.61374
訓練資料 6644 筆, 設定 batch size=26, 每 run 完一個 epoch, 需要把 6644 每次執行 26筆, 所以需要執行 256 次才能把資料都跑完一遍, checkpoint 就是這個迴圈跑一圈等於一個 checkpoint.
假設上面的設定值每 run 一個 epoch, 需要 300 秒. (5分鐘), 每 1 epoch 要吃掉 256單位的 checkpoint, 希望每 10分鐘存一次 checkpoint, 那 checkpoint 請設定為 512 即可. - 重覆訓練少量資料的影響
比如說,有幾個部件在 infer 的結果看起來因為寫法差異太大,所以初期效果很差,會有很明顯的某一筆畫中斷,中間有大面積的白色,剛好上半部是像思源,下半部是要學習的筆跡,如果只取出要加強的學習的某些圖片,重覆地學習,的確就會愈來愈像要學習的筆跡,相對其他沒有去練習的部件,就會明顯被弱化,infer 出來的就會變糊糊的。這個似乎沒有辦法避免,只好再做幾次完整(所有部件)的訓練,在接著使用完整的部件再去訓練個60個epoch,結果剛才加強訓練的成果似乎被稀釋掉,又打回加強訓練前的模樣,有可能是受到其他訓練資料的交互影響,有訓練還是有差別,有些其他部件的小細節有增加的更有連貫性,外型較清晰。
二個在學習的字跡差異太大,會「大量」增加學習的負擔,所以最好可以選擇在「寫法」或「筆觸」都相近的字體來學習,效率上會好很多,不一定要用思源黑體或思源宋體去學,只是使用思源家族,可以 infer 出來的字集會比較完整。在「選擇要學習的2個字跡」有點難取捨。
最佳的情況就是要學習的字跡超級的工整,這是最佳、最省時間的情況,但似乎很難遇到。很多手寫字型的部件,會遇到出現的位置不太固定,也會造成學習效果較慢。
有部份作者的風格有點特殊,相同的部件有時是曲線,有時是直角,也會造成學習上的困難。 - 重覆訓練高筆畫數造成的影響
如果高筆畫數的字與低筆畫數一起訓練, 從推論結果來看, 高筆畫數的細節不容易正確判斷, 但針對高筆畫數增加訓練, 遇到複雜筆畫的結果有顯著改善, 但相對會讓低筆畫數的長線條產生影響, 影響是線條的寬度可能不能保持一持性, 會微微的造成短暫的鋸齒狀. - learning rate decay
要設多少才開始 decay, decay 的影響是什麼?目前程式的參數(schedule)預設值是 20.
也可以挑戰一直訓練,不要產生 decay, 但這樣就會訓練的較慢。Decay 會不會讓訓練速度提升? 實際測試每一個 Epoch 在 decay 前與 decay 後, 花費的時間一樣.
目前程式 decay 效果是 learning rate 從 1.0 到 0.5, 初期 decay 訓練出來的結果會有大量的波紋與大量的雜訊,但再持續訓練後,線條就會平滑許多,有些多的雜點明顯少掉很多。要解決雜點, 可以挑戰再使用另一個新的模型來進行學習,用來去除雜點與讓線條光滑。
大約訓練到第 30小時之後,每次decay 會很明顯會破壞畫質,會產生大量的雜點或分叉。
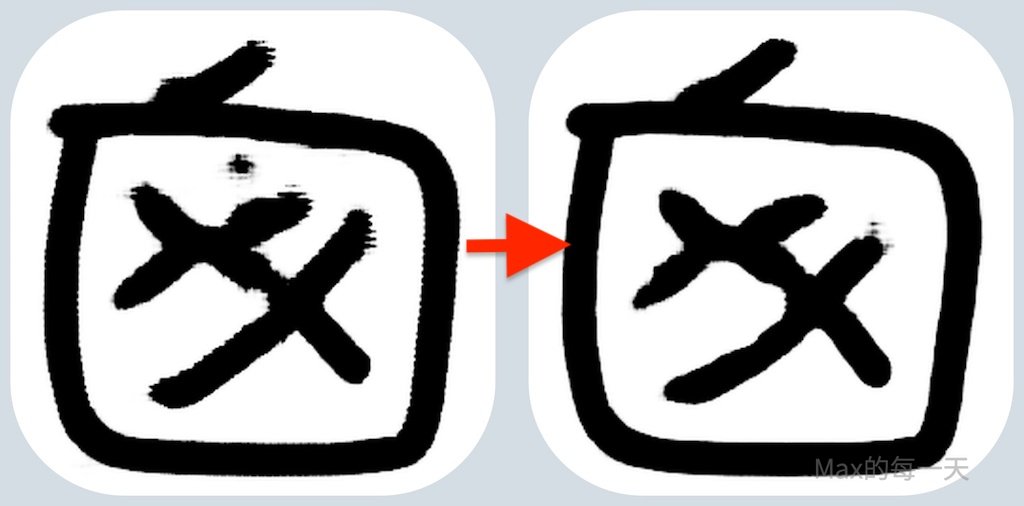
下圖是某一個字在訓練過程的變化, 大約每一個單位是 15 個Epoch 左右, 初期算出來的筆畫之間會有很明顯的暈染, 大約到第3階段會開始出現雜點, 到第4階段就算差不多完成了.

learning rate 相關說明:
https://stackoverflow.max-everyday.com/2025/02/zi2zi-pytorch-initial-learning-rate-0-001/
建議訓練的中/後期, 不要使用 0.001 來訓練, 記得增加 –lr=0.0005 參數, 從 0.0005 開始訓練, 可以避免比較不會長出雜點, 其實長出雜點的解法也很容易解決, 可以用訓練出來的, 再次做訓練, 就幾乎沒雜點.
- 中文/英文/符號要一起訓練嗎?
如果筆跡的規則簡單,一起訓練滿省事,但是一般的情況下,建議分開訓練會好一些,變數較少,問題會較少。而且部份有風格的字型,中文字套用的風格跟英文不太一樣。 - 訓練資料「多對一」的問題
手寫字型每個字都是獨特的存在,如果使用思源黑體,比如”女”的部件,在工整的思源黑體或宋體,女出現的位置幾乎會相同情況下,拿來訓導的資料卻都是不一致的寫法,如此,預測難度變的極高,產生的結果會偏向平均值,且較模糊。
有曾經遇到一個字型,規則明明就很簡單,應該很容易可以訓練出來,例如「斥」部件,很奇怪,餵了很多「斤」與「斥」部件的資料,訓練了6小時,某一些部件就是訓練不出來,筆畫會中斷,推測應該是先使用思源黑體CJK JP去學習,但對「點」的寫法遇到不一致的情況,然後再改用思源黑體CJK TC去推論,CJK JP與TC 剛好在 刃、斥、凡、丸系列的寫法不剛,造成AI在訓練初期的障礙。 - 訓練出來的結果比原作者對齊位置更準確,規則更一致
有些成功訓練出來的字,會比原作者的規則更明確,也可能是因為AI學習到的統計值偏向平均值,所以套用出來的規則沒辦法很多個,以下圖來說,黑色是原作者,套用圓角的時間點有特定的規則,有時是圓角,有時是直角,AI訓練出來是紅字部份,幾乎都是套出圓角風格,如果把特定規則的字與一般規則的值,都一起訓練時,就會產生特定規則的字的權重被一般規則同化掉。這個解法,需要把這種有特殊規則的字挑出來,增加訓練次數,就可以增加特定規則的權重。
就是對齊、中宮緊與鬆的配置比例,AI訓練出來結果常常優於對空間感較遲鈍的我們一般人。

- 原作者的例外
預期應該使用一樣的寫法, 但作者有獨特的見解, 所以訓練結果變的很奇怪…, 常見的字有: 僅勤謹槿瑾漢艱傳轉專

建議解法: 原作者的獨特見解的字, 應該排除到訓練的清單裡, 這個等最後字型產生出來後, 再手動去調整。
- 訓練資料「一對多」的問題
下圖預期這一列, 分別使用了字型A, 與思源黑體, 對於【子】的部件,在思源黑體是沒有彎曲與襯線, 但在字型A 就有, 這變成在思源黑體裡同一個規則到了字型A 會有二個情況產生, 這個子的寫法, 常見的字有: 仔子李孖存

建議解法:
- 方案1:用力地增加訓練次數就可以解決, 但這個變成很累與花時間,
- 方案2: 比較簡單的解法是針對有問題的這種一對多的, 另外再使用特殊的分支來訓練特定的字, 會簡單與省時間一點, 但缺點就是要增加人工的介入.
- 原作者的筆畫不一致
立與言, 在日文裡長很像, 該選擇變成水平線還是垂直線, 作者可能也會搞混.

想知道某一個部件在字型中出現的情況, 先到部件查詢網站:
查詢目前字型對映到那些字的實作: https://codereview.max-everyday.com/remove-selected-char/
勺 應該水平還是斜線, 沒想到思源黑體用的是水平線, 出乎意料之外, 常見字: 勺杓釣豹灼

還有一些, 很容易產生寫法不同的字, 例如: 巳等部件, 常見字: 瞥敝幣弊斃蔽鼈, 靜清瀞淨淫雞, 卷券倦捲綣, 益溢.
戶部寫法不同: 扇煽搧戶房翩諞,
者部寫法不同: 堵屠著賭睹豬潴瀦箸薯藷諸覩赭躇闍,
肖部寫法不同: 肖屑消哨俏鎖蛸鞘
火部寫法不同,
壬寫法不同, 例如: 筳, 在 cjktc 是土, 在 cjkjp 是士.
俞部寫法不同: 愈俞偷愉逾瘉覦
示部寫法不同: 神榊, 祁祇

食部寫法不同: 食飯, 榔朗郎瑯螂, 蝕餅飴餐餓
羽部寫法不同: 溺弱鰯, 濯擢耀燿躍
巳部寫法不同: 包抱胞鞄泡砲,
東部寫法不同: 東柬煉練鍊闌爛瀾
酋部寫法不同: 酋猶猷尊噂楢樽蕕
曾部寫法不同: 曾僧噌增甑

冬部寫法不同, 沒想到冬和羽一樣, 有不同寫法, 常見有: 疼螽

曷部寫法不同: 曷葛偈掲揭喝
彥部寫法不同: 薩產顏顔彥諺
組合起來的比例不同: 鏖魘

說明: 訓練過半的話, 會以目標筆畫為準, 訓練還沒過半的話, 會以來源 (我的個案是思源黑體) 為準, 要省時間的話, 這個字最好不訓練.
建議解法: 看是要幫原作者修改, 或是先從訓練清單裡移除.
豕部寫法不同: 劇墜壕嫁家據曚朦檬毅溷濛濠瀦燧燹矇稼糘艨蒙豕豚豢豪豬逐遂遯遽邃醵隊隧

解法: 墜壕嫁家據曚朦檬濛濠瀦矇稼糘艨蒙豕豚豪遯遽醵隊, 這幾個字從 cjktc 拿來訓練, 再手動調整一下寶蓋頭斜線與直線的問題.
Q: 針對已經訓練一段時間的模型的 checkpoint, 發現某幾個字的 infer 結果不滿意, 進而發現筆晝的對應應該要調整, 這時候應該從頭訓練, 還是排除有問題的, 進行接續訓練?
A: 這個問題, 似乎沒有標準答案, 因為不管選擇那一個, 都很花時間. 實際測試, 猜測選”重新訓練”會比較省時間.
這個問題有2種情況, 個案是寫法不同造成學習效果差, 例如: 羽字, 是要使用二條平行線, 還是一個直角, 一是找到的標準答案, 這時候就可以只去訓練標準答案來修正, 這個要生出標準答案還滿簡單, 但有些字要生出標準答案就很難, 例如: 鏖魘.
或是針對有問題的這些字, 改用重新訓練的版本, 其他大部份的字, 使用已經訓練一陣子的版本, 如果針對不同輸出的字, 使用不同的 checkpoint 版本(Interpolation) 會讓風格程度不同, 也很麻煩.
實際測試, 被消除掉的線條, 讓訓練到可以長出新的線條, 很花時間.
總結, 針對同一個字, 因為來源與目的風格差異很大而且筆畫規則不同的二個圖片, 最好不要做訓練, 或是修改一下要訓練的字的來源與目的圖片, 消除掉有問題的筆畫, 讓其他部份的筆畫還可以持續訓練.
實際測試把筆畫規則不同的筆畫先用繪圖軟體刪除之後, 例如: 有點點的者, 在訓練前, 先同步訓練資料都是沒有點的者, 訓練次數增加很多之後, 即使輸入有點點的者, 也會拿到沒有點的者, 這個意思是說, 訓練資料必需先準備好有點的, 與沒點的, 不然訓練出來都會只有一種結果, 如果訓練的次數沒有很多的情況下, 有點的者輸入的情況下, 可以產生出有點的者.
有一個已經花了很多時間訓練的模型, 發現有一個字推論結果看起來筆畫怪怪的, 才發現是對應有問題: 寧

說明: 左圖是推論結果, 右圖是, 訓練的對照表.
解法: 要把這2種情況餵進去做訓練.

說明: 手動做出這2張圖, 丟進去做訓練.
在額外訓練2百個 epoch, 筆畫就長出來了, 但很花時間, 一開始有正確的資料很重要.

欠的人, 該不該相連? 下面是 zen maru 規則沒一致, 接下來遇到的問題是, 要用來推論的 noto sans 居然讓規則一致了. @_@; ….

面對作者, 對於部件使用不同規則, 該怎麼處理?
韋規則不一致:

結論: zen maru 的圍幃, 跟其他不一致, 這個問題在 noto sans cjktc 上滿複雜的, 居然有很多種寫法!
超過框框的字要如何處理?
請參考: https://stackoverflow.max-everyday.com/2025/02/zi2zi-image-over-flow/
日文字沒有出現的符號, 要怎麼訓練?
有些符號, 訓練的資料裡可能完全沒出現過, 例如:
- 辵部: 有二點與一點的差別, 追槌樋進近,蓬遊鏈
- 草部: cjktc 是完全分開, 而且還有一些例外, 例如: 歡觀勸敬驚警灌夢等字, 不算是草.
- 還有很多寫法不同, 例如: 艹女糹糸辶肉月言雨羽青兌直真戶北㕣台厶酋宀亠肖俞礻包東丷曾冬曷彥豕
解法參考: https://stackoverflow.max-everyday.com/2025/02/zi2zi-unseen-data/
實際測試, 不同語言最好分開訓練, 因為同一個模型要去判斷不同語言, 難度太高, 雖然輸入的資料已經有加入 cjktc, 但實際上會推論出介於 cjktc / cjkjp 之間的草字頭. 有一些由於訓練資料的 cjktc 的草頭很接近, 留白處很少, 而 cjkjp 是幾乎相連, 因為訓練出來的結果, 會是極為接近的草字頭, 不符合預期, 但以輸入的資料來說又很合理.
要給cjktc 的模型, 在接近穩定時, 不要放入 cjkjp 與 cjktc 相沖突的資料.
太細與太粗的線條, 容易推論錯, 預期應該是圓形筆觸, 變成方形.
解法: 改用 512×512 解析度訓練.
discriminators file size:
- 512×512 在 discriminators 的 final_channels=256 情況下, file size=174MB
- 512×512 在 discriminators 的 final_channels=128 情況下, file size=89MB
- 256×256 在 discriminators 的 final_channels=512 情況下, file size=98MB
- 256×256 在 discriminators 的 final_channels=256 情況下, file size=27MB
在訓練量次數少的情況下, epoch < 10, final_channels 差一倍情況下, 推論結果沒有顯著差異.
Batch size 的選擇, colab 的 15GB RAM 的情況下, 取決於模型的大小,
- 512×512, batch size 大約在 32 – 36.
- 256×256, 的 batch size 可以在 144-152
建議, RAM 使用在 13.0GB ~ 14.5 GB 之間比較安全, 有時候是在 epoch 0 的後半部資料訓練時才 torch.OutOfMemoryError: CUDA out of memory.
訓練花費時間, 訓練資料在 7000筆左右.
- 512×512, 1個 Epoch, 大約 1320秒,
- 256×256, 1個 Epoch, 大約 450秒,
512×512,
Epoch: [ 0], [ 0/ 235] time: 21.60, d_loss: 5.16978, g_loss: 23.27426, category_loss: 0.01193, cheat_loss: 2.28568, const_loss: 0.24754, l1_loss: 20.74104
Epoch: [ 0], [ 100/ 235] time: 573.34, d_loss: 7.10198, g_loss: 23.13695, category_loss: 0.00000, cheat_loss: 1.06090, const_loss: 0.21971, l1_loss: 21.79716
Epoch: [ 0], [ 200/ 235] time: 1125.35, d_loss: 4.77741, g_loss: 26.83415, category_loss: 0.08033, cheat_loss: 3.22208, const_loss: 0.25817, l1_loss: 23.35390
Epoch: [ 1], [ 0/ 235] time: 1324.45, d_loss: 4.68911, g_loss: 24.61167, category_loss: 0.00790, cheat_loss: 2.40229, const_loss: 0.33275, l1_loss: 21.87663
256×256
Epoch: [ 1], [ 0/ 45] time: 458.64, d_loss: 25.33166, g_loss: 59.14429, category_loss: 0.00000, cheat_loss: 32.10165, const_loss: 0.05294, l1_loss: 26.98970
Epoch: [ 2], [ 0/ 45] time: 909.97, d_loss: 18.75299, g_loss: 46.67240, category_loss: 0.00000, cheat_loss: 24.54880, const_loss: 0.06139, l1_loss: 22.06221
EuphoriaYan 的參數調整
主要調整在 net_D部分倒數第二層加了个1 x 1的卷積, 程式碼:
https://github.com/EuphoriaYan/zi2zi-pytorch/blob/master/model/discriminators.py
def __init__(self, input_nc, embedding_num, ndf=64, norm_layer=nn.BatchNorm2d, image_size=256):
"""Construct a PatchGAN discriminator
Parameters:
input_nc (int) -- the number of channels in input images
ndf (int) -- the number of filters in the first conv layer
norm_layer -- normalization layer
"""
super(Discriminator, self).__init__()
if type(norm_layer) == functools.partial: # no need to use bias as BatchNorm2d has affine parameters
use_bias = norm_layer.func != nn.BatchNorm2d
else:
use_bias = norm_layer != nn.BatchNorm2d
# as tf implement, kernel_size = 5, use "SAME" padding, so we should use kw = 5 and padw = 2
# kw = 4
# padw = 1
kw = 5
padw = 2
sequence = [
nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw),
nn.LeakyReLU(0.2, True)
]
nf_mult = 1
nf_mult_prev = 1
# in tf implement, there are only 3 conv2d layers with stride=2.
# for n in range(1, 4):
for n in range(1, 3): # gradually increase the number of filters
nf_mult_prev = nf_mult
nf_mult = min(2 ** n, 8)
sequence += [
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=2, padding=padw, bias=use_bias),
norm_layer(ndf * nf_mult),
nn.LeakyReLU(0.2, True)
]
nf_mult_prev = nf_mult
nf_mult = 8
sequence += [
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=1, padding=padw, bias=use_bias),
norm_layer(ndf * nf_mult),
nn.LeakyReLU(0.2, True)
]
# Maybe useful? Experiment need to be done later.
# output 1 channel prediction map
sequence += [nn.Conv2d(ndf * nf_mult, 1, kernel_size=kw, stride=1, padding=padw)]
self.model = nn.Sequential(*sequence)
# final_channels = ndf * nf_mult
final_channels = 1
# use stride of 2 conv2 layer 3 times, cal the image_size
image_size = math.ceil(image_size / 2)
image_size = math.ceil(image_size / 2)
image_size = math.ceil(image_size / 2)
# 524288 = 512(num_of_channels) * (w/2/2/2) * (h/2/2/2) = 2^19 (w=h=256)
# 131072 = 512(num_of_channels) * (w/2/2/2) * (h/2/2/2) = 2^17 (w=h=128)
final_features = final_channels * image_size * image_size
self.binary = nn.Linear(final_features, 1)
self.catagory = nn.Linear(final_features, embedding_num)說明: 這個調整影響滿大的, 相關說明:
https://stackoverflow.max-everyday.com/2025/02/zi2zi-pytorch-discriminator-final-channels/
但是看一下網路上其他解法, 似乎大家也把 final features 也設成 1:
https://github.com/iamyufan/MF-Net/tree/main/models
實際測試, final_channels = 1 與 final_channels = 512 訓練 regular style 的結果, 效果差不多.
增加2個殘差塊(ResidualBlock)與1個自注意力機制層後, 訓練相同資料花費時間的比較:
預設的 8層, 訓練的是思源黑體Regular字重
unpickled total 6644 examples
Epoch: [ 1], [ 0/ 47] time: 381.12, d_loss: 1.36874, g_loss: 5.04551, category_loss: 0.00000, cheat_loss: 0.73770, const_loss: 0.02055, l1_loss: 4.28725
unpickled total 6644 examples
Epoch: [ 2], [ 0/ 47] time: 745.10, d_loss: 1.38180, g_loss: 4.90196, category_loss: 0.00000, cheat_loss: 0.70541, const_loss: 0.01073, l1_loss: 4.18582
Checkpoint: save checkpoint step 100
預設的 8層+2個殘差塊(ResidualBlock)與1個自注意力機制層, 訓練的是思源黑體Regular字重:
unpickled total 6644 examples
Epoch: [ 1], [ 0/ 47] time: 470.44, d_loss: 1.34245, g_loss: 15.51074, category_loss: 0.00147, cheat_loss: 0.59637, const_loss: 0.04504, l1_loss: 14.86819
unpickled total 6644 examples
Epoch: [ 2], [ 0/ 47] time: 946.34, d_loss: 1.32939, g_loss: 13.35053, category_loss: 0.00094, cheat_loss: 1.01953, const_loss: 0.05043, l1_loss: 12.27941
預設的 8層+2個殘差塊(ResidualBlock)與1個自注意力機制層, 訓練筆劃較細的思源宋體Regular字重:
unpickled total 6665 examples
Epoch: [ 1], [ 0/ 46] time: 433.91, d_loss: 2.99246, g_loss: 32.46876, category_loss: 0.29926, cheat_loss: 0.96215, const_loss: 0.03789, l1_loss: 31.40315
unpickled total 6665 examples
Epoch: [ 2], [ 0/ 46] time: 862.37, d_loss: 1.94354, g_loss: 28.66256, category_loss: 0.00794, cheat_loss: 1.22368, const_loss: 0.04419, l1_loss: 27.39224
說明: 以相同的思源黑體Regular字重來說, 從 381秒增加為 470秒, 增加約 23% 的時間.
文字的推論 (infer)
分享推論的相關心得.
- 應該用 CPU 還是 GPU 進行 infer?
家的不到2萬的中古筆腦的 GPU 只有 4GB RAM, 一次推論的量很少, batch_size 設在 26 就用滿 4GB RAM了, 一次推論完 44,000 個字, 大約需要1小時, 但是在 colab 推論, 相同的程式碼, 大約 10分鐘之內, 或更短的時間就全部都推論完, 因此建議在 colab 上進行推論, 分享colab 上的部份指令:
Clone source code to colab HDD
%cp -rf '/gdrive/My Drive/Colab Notebooks/zi2zi-pytorch' /root/
%ls -al /root
%pwdMake potrace executeable
%cd /root/zi2zi-pytorch/
!chmod +x /root/zi2zi-pytorch/potrace
%ls -alInfer to colab HDD (Full)
%cd '/root/zi2zi-pytorch'
!python infer.py --experiment_dir=experiments \
--experiment_checkpoint_dir=experiments/checkpoint \
--input_nc=1 \
--gpu_ids=cuda:0 \
--batch_size=256 \
--resume=204 \
--from_txt \
--generate_filename_mode=unicode_int \
--src_font=source/font/SweiGothicCJKsc-Regular.ttf \
--src_font_x_offset=0 \
--src_font_y_offset=0 \
--src_txt_file=charset/charset_SweiGothicCJKsc-Regular.txt \
--crop_src_font \
--anti_alias=10 \
--image_ext=pbm \
--skip_exist \
--resize_canvas_size=1000 \
--label=25Convert infered result to SVG
%cd '/root/zi2zi-pytorch'
!python sh/bmp_to_svg.py --input experiments/infer/25 --output experiments/infer/25_svg這個 bmp_to_svg script, 請參考: 批次轉換目錄下的 bmp 為 svg 檔
https://codereview.max-everyday.com/bmp-to-svg/
potrace 外部指令的取得, colab 環境請下載 linux-x86_64 的版本.
https://potrace.sourceforge.net/#downloading
Sync checkpoint from google driver to colab
%cd ‘/gdrive/My Drive/Colab Notebooks/zi2zi-pytorch/experiments/checkpoint-old-maruko’
%cp *.pth /root/zi2zi-pytorch/experiments/checkpoint
%ls -al /root/zi2zi-pytorch/experiments/checkpoint
Sync font file from google driver to colab
%cd '/gdrive/My Drive/Colab Notebooks/zi2zi-pytorch/source/font'
%cp *.ttf /root/zi2zi-pytorch/source/fontPackage as tar from colab HDD to google driver
%cd '/root/zi2zi-pytorch'
!tar -cvzf infert_204_regular_cjksc_svg.tar experiments/infer/25_svg
%cp /root/zi2zi-pytorch/infert_204_regular_cjksc_svg.tar '/gdrive/My Drive/Colab Notebooks/zi2zi-pytorch/experiments'以上就可以取得 svg 檔, 並推回 google, 後續就是使用 import svg 就可以取得字型的檔案, 參考:
https://codereview.max-everyday.com/import-svg-to-font/
- 應該用 CPU 還是 GPU 進行 infer?
結論是, 用便宜的GPU 也跑的比 CPU 快,
infer 文字數目 646個, 實測便宜的遊戲用GPU, 只有 4GB, 的 batch size 可以設到 24, 使用 CPU infer 花費 188秒 , 使用 GPU 花費 118秒, 有時候是跑出 117秒, 相差一點點, GPU 的執行時間, 大約是CPU 的 2/3, 算滿快的.
# AMD CPU RYZEN 5000 series 電池模式
cold start time: 190.53, hot start time 188.99
# NVIDIA GeForce GTX 1650, GPU 4GB, 電池模式
cold start time: 119.82, hot start time 118.17
# AMD CPU RYZEN 5000 series, 插電模式.
cold start time: 106.89, hot start time 105.93
# NVIDIA GeForce GTX 1650, GPU 4GB, 插電模式.
cold start time: 119.82, hot start time 71.50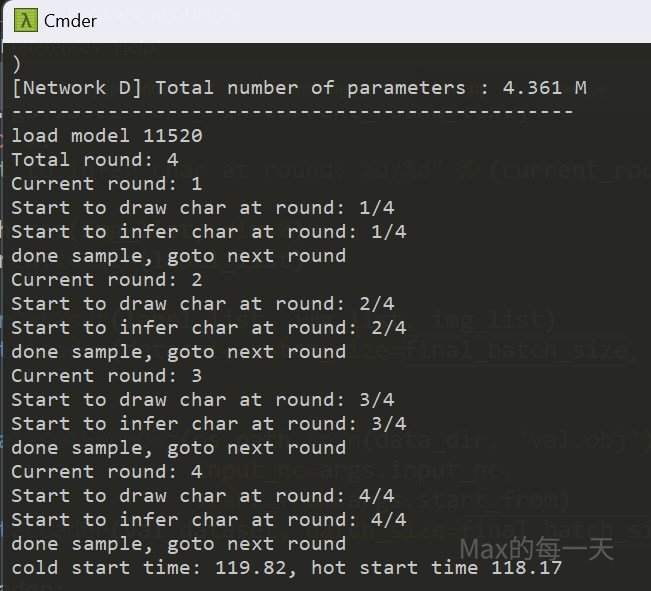
推論 batch size 的選擇:
使用 4GB 的 GPU, batch size=48 時, 執行到第二 round 會掛掉, 因為記憶體不足, 執行指令: torch.cuda.empty_cache() 即可解決, infert 111 chars, 執行結果:
load model 5
Total round: 3
Current round: 1
Start to draw char at round: 1/3
Start to infer char at round: 1/3
Current round: 2
Start to draw char at round: 2/3
Start to infer char at round: 2/3
Current round: 3
Start to draw char at round: 3/3
Start to infer char at round: 3/3
cold start time: 34.55, hot start time 31.77
如果使用 batch size=32, 不清 cuda cache 反而比較快:
load model 5
Total round: 4
Current round: 1
Start to draw char at round: 1/4
Start to infer char at round: 1/4
Current round: 2
Start to draw char at round: 2/4
Start to infer char at round: 2/4
Current round: 3
Start to draw char at round: 3/4
Start to infer char at round: 3/4
Current round: 4
Start to draw char at round: 4/4
Start to infer char at round: 4/4
cold start time: 32.51, hot start time 29.90
Youtube 影片
AI造字經驗分享
https://youtu.be/-2V5H_4kSg4
深度學習崛起,企業擁抱AI
科技大廠們,紛紛押寶AI,也帶動一般企業投資AI,但企業要如何運用科技,促成商業發展?企業在使用AI 要來解決什麼問題?要使用什麼演算法?要套用那一個模型?會遇到什麼資安或相關法規。這些問題,我都沒有答案,但google 一下,似乎很多文章都有回答這類問題。
相關法規最近的新聞報導:麥當勞被指控違反伊利諾伊州的BIPA( Biometric Information Privacy Act,生物識別資訊隱私法),在使用語音識別技術接受訂單、收集聲紋資訊之前,沒有經過他的同意,也未告知這些資訊的處理方式、儲存時間等內容。
反正,AI 是趨勢,有空時多接觸看看。也許,有一天用的到,而且萬一將來真的要去學的話,會比較好理解。
相關文章
苦累蛙圓體 Kurewa Gothic
https://max-everyday.com/2021/06/kurewa-gothic/
馬路口圓體 Maruko Gothic
https://max-everyday.com/2021/07/maruko-gothic/
github – zi2zi-pytorch
https://github.com/max32002/zi2zi-pytorch
學習字體的筆記
https://codereview.max-everyday.com/font-readme/
AI 造字相關問題
https://codereview.max-everyday.com/font-readme/#stackoverflow
AI相關實作
https://codereview.max-everyday.com/font-readme/#implement

