要切換 models 只要在設定界面點「設定」就可以看到預設值是使用 Base Multilangual Quantized, 把預設值切換到 medium multilingual quantized 5_0 就可以取得很棒的轉換效果。
base 與 medium 推論比較
同一個影片, base 推論結果:
1
00:00:00,000 --> 00:00:07,040
哈喽大家好,我是MACS,今天要來分享諾貝爾的小故事
2
00:00:07,040 --> 00:00:11,240
他是一個意外獨到自己復魂的男人
3
00:00:11,240 --> 00:00:14,640
作為一個很快一世紀的製者
4
00:00:14,640 --> 00:00:20,440
93歲的巴菲特,他寫給古端的高別姓已經被管瘋的分享
5
00:00:20,440 --> 00:00:24,400
近週呢,有涵蓋很多不同領域的重點medium 推論結果:
1
00:00:00,000 --> 00:00:03,000
哈囉大家好,我是Max
2
00:00:03,000 --> 00:00:07,000
今天要來分享諾貝爾的一個小故事
3
00:00:07,000 --> 00:00:11,000
他是一個意外讀到自己復魂的男人
4
00:00:11,000 --> 00:00:14,000
作為一個橫跨一世紀的智者
5
00:00:14,000 --> 00:00:16,000
93歲的巴菲特
6
00:00:16,000 --> 00:00:20,000
他寫給股東的告別信已經被廣泛的分享
7
00:00:20,000 --> 00:00:24,000
信中有涵蓋很多不同領域的重點medium model 效果真的好很多, 可以省下很多修改的時間, 但是與其使用 shotcut 不如自己直接用 python 來取得字幕內容, 參考:
Whisper
https://github.com/openai/whisper
Robust Speech Recognition via Large-Scale Weak Supervision
如果要讓文字轉語音, Shotcut 也增加支援:
KokoroDoki: Real-Time Text-to-Speech (TTS)
https://github.com/eel-brah/kokorodoki/
Natural-sounding Text-to-Speech App that fits anywhere. Fast, Real-Time and flexible.
目前 Shotcut 25.10.31 附的 whisper 缺點
在明明有 GPU 但似乎程式無法檢測到, 不管是在 base model 或 medium model, 這個造成都是使用 CPU 進行推論, 造成如果使用較大的 medium model ,推論所需要的執行時間變的很長!
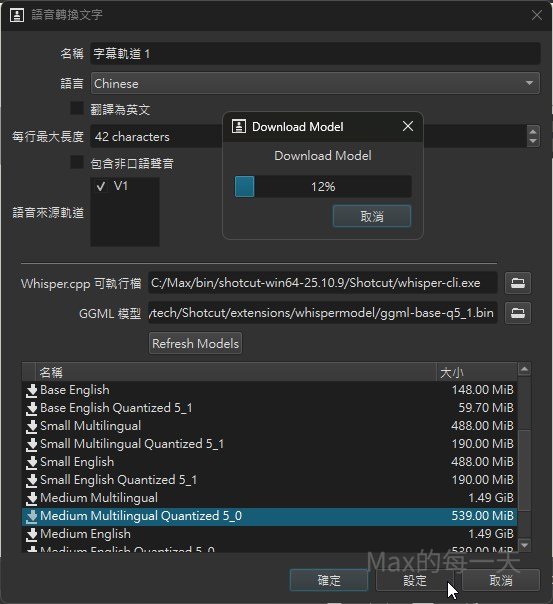
下載的 .bin 並沒有存在 shotcut 目錄下, 所以 shotcut 切換版本, 不需要重新下載 whisper 的 model, 缺點也變成, 移除 shotcut 記得要再去移除 .bin 檔, 不然真的肥大.
Base Multilingual 與 Quantized 的差異
這兩種模型都是基於相同的 Base Multilingual 架構訓練出來的,因此它們的語言能力範圍和基本架構是相同的。
主要的差異在於模型的儲存方式和計算精度,這會直接影響檔案大小、記憶體需求和執行速度。
| 特徵 | Base Multilingual (非量化/標準 FP16) | Base Multilingual Quantized (量化) |
| 定義 | 模型的權重參數使用標準的 16 位浮點數 (FP16) 或 32 位浮點數 (FP32) 儲存。 | 模型的權重參數被壓縮成較低位元(例如 4 位、5 位或 8 位整數)儲存。 |
| 檔案大小 | 較大。例如 Base Multilingual 可能約 140MB。 | 極小。通常只有原始大小的 30% 到 60% (約 40MB 到 80MB)。 |
| 記憶體 (RAM) 需求 | 較高。 | 低得多。佔用的記憶體更少。 |
| 執行速度 | 標準速度。 | 通常更快。由於傳輸的資料量減少,CPU 或 GPU 的推論速度可以更快。 |
| 準確度 | 最高(在該模型尺寸下)。 | 略微下降。由於精度損失,理論上準確度略低,但對大多數日常用途來說,差異可以忽略不計。 |
| 使用情境 | 資源充裕的伺服器或追求極致準確度時。 | 資源有限的設備(如 Shotcut 依賴的 CPU),追求快速、低資源消耗時。 |
ggml-base-q5_1.bin 就是一個 Quantized 模型(q5_1 指的是 5 位元的量化)。
Shotcut 內建 Whisper 喜歡使用量化模型,是因為它具有以下優勢:
- 速度: 在 CPU 上執行時,量化模型計算更快,降低了語音轉文字所需的總時間。
- 效率: 佔用的磁碟空間和 RAM 資源少,適合整合到應用程式中,減少了使用者下載和執行的負擔。
Shotcut 內建或自動下載的Whisper 模型儲存路徑
Shotcut 內建或自動下載的 Base Multilingual Quantized 模型(例如 ggml-base-q5_1.bin 或類似的量化版本),通常會存放在 Shotcut 的 應用程式資料 (App Data) 目錄下的特定子資料夾中。
以下是根據您提供的日誌和標準 Windows 平台的具體路徑:
這個目錄位於 Windows 的隱藏資料夾 %LOCALAPPDATA% 中:
- 完整路徑範例 (基於您的日誌):
C:\Users\max\AppData\Local\Meltytech\Shotcut\extensions\whispermodel\ - 通用路徑 (您可以直接在檔案總管地址欄輸入):
%LOCALAPPDATA%\Meltytech\Shotcut\extensions\whispermodel\
(如果您的帳號是 max)