
在處理教學影片、訪談、Podcast 或逐字稿影片時,常見的需求是:只保留「有字幕的內容」,自動剪掉中間的停頓、空白或無聲段落。如果手動在剪輯軟體中一段段對齊字幕,不但耗時,也容易出錯。
這篇文章會帶你使用圖形化的設定介面,讓你不必記憶複雜的指令,即可透過滑鼠點擊完成剪掉影片空白段落。想了解複雜指令有附在下半部。
這套腳本,能自動刪除空白片段並保留語意內容。核心邏輯是先將影片轉成單聲道 MP3,再透過 OpenAI Whisper 生成 SRT 字幕。最後根據字幕的時間軸,利用 ffmpeg 進行影片裁切與合併。
建議安裝 AI 相關的 CLI, 使用指令: “幫我修正字幕檔的用字錯誤, 例如: 勇唱改為詠唱”
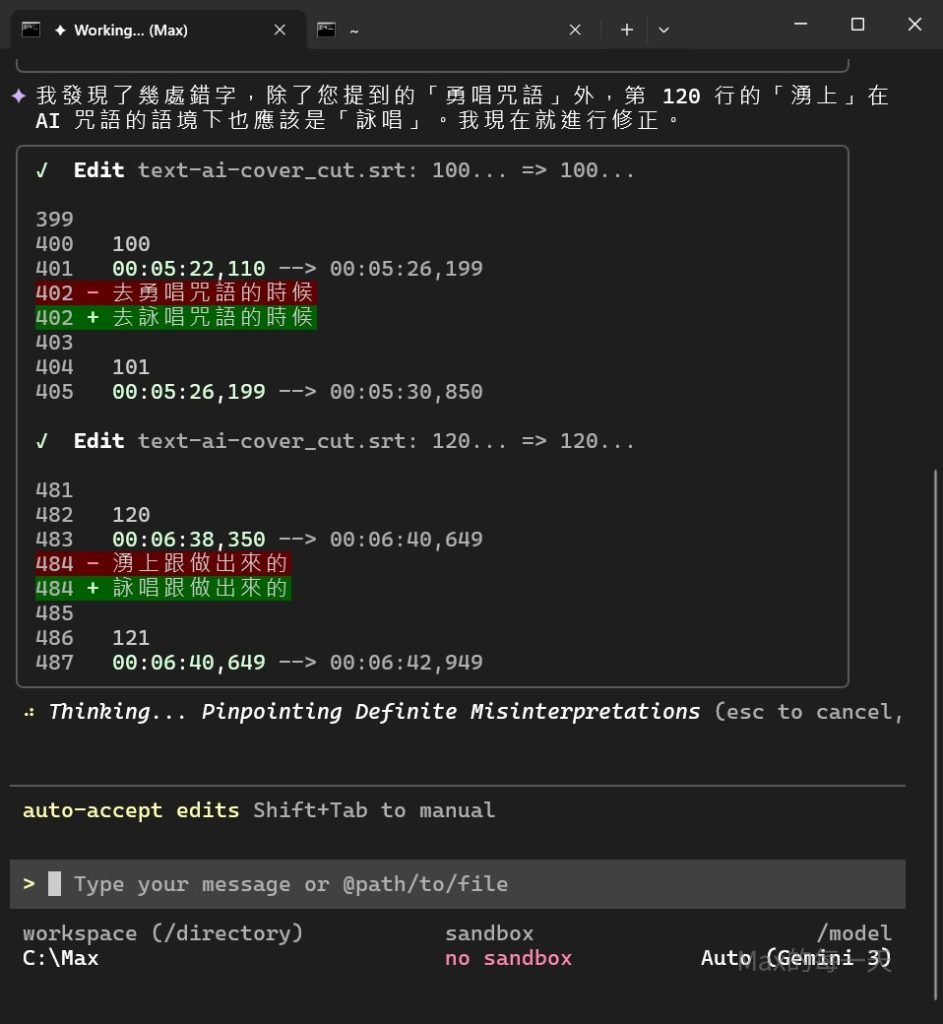
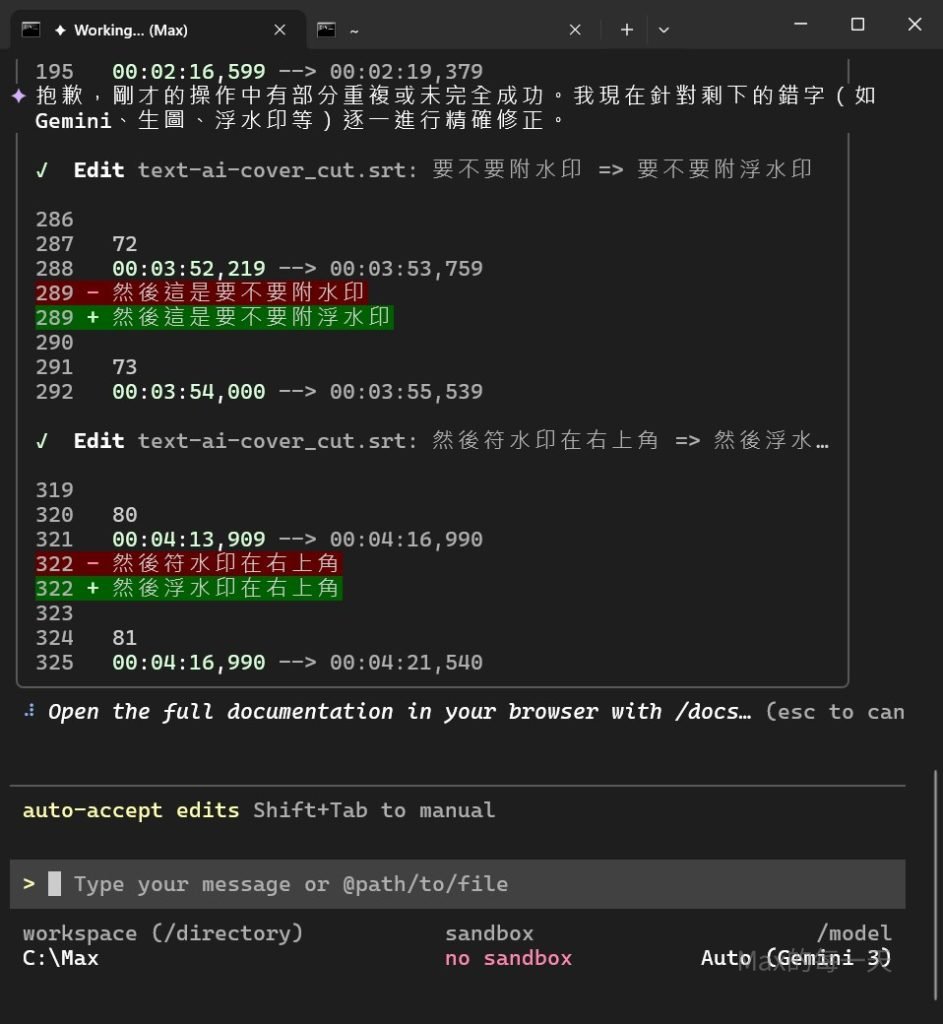
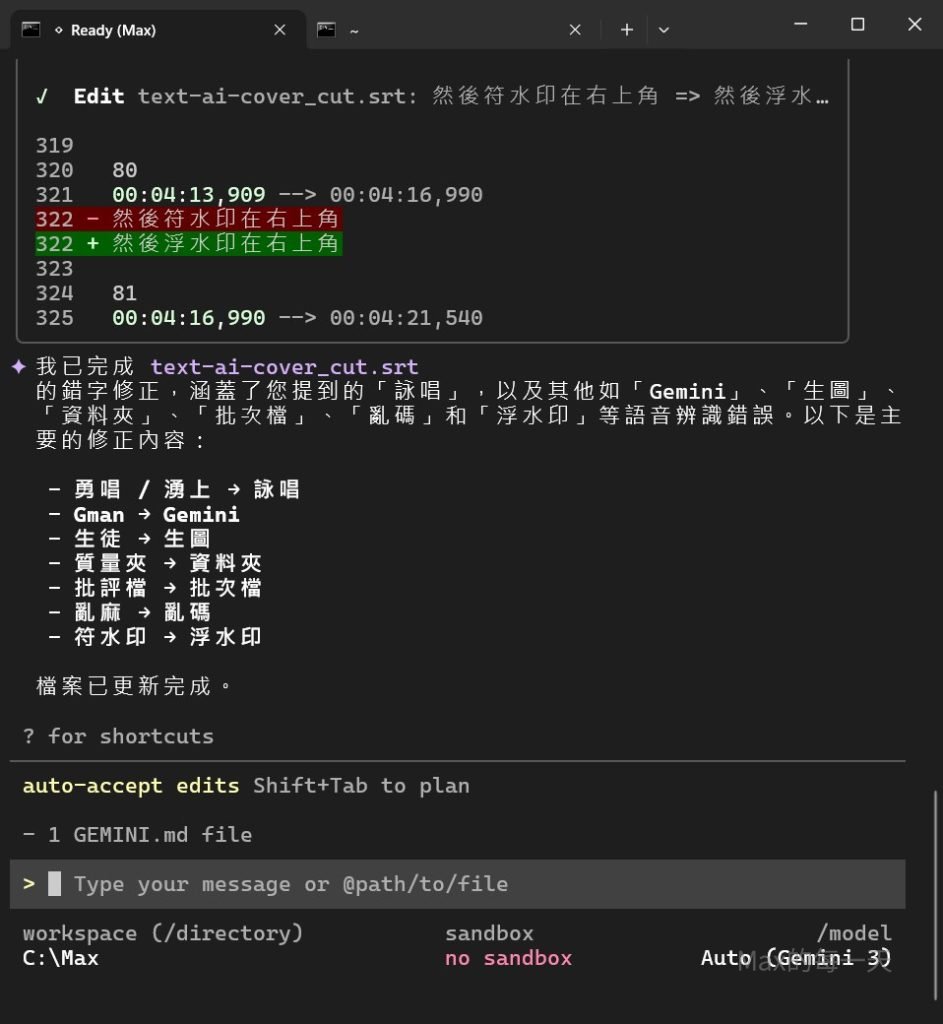
超讚的, 省下好多校稿的時間.
AI CLI(命令列介面)已經從單純的對話工具演進為能直接操作檔案、執行指令甚至修復 Bug 的智慧代理人(AI Agents)。以下是目前主流且功能強大的 CLI:
- Claude Code:由 Anthropic 推出。它能理解複雜的專案架構,適合進行大規模重構(Refactoring)或修復測試失敗。它的強項在於強大的邏輯推理能力。
- Aider:開源社群非常受歡迎的工具。它能與 Git 深度整合,每次修改程式後會自動生成適當的 Commit Message。它支援多種模型(如 GPT-4o, Claude 3.5/3.7)。
- Gemini CLI:Google 推出的官方工具。特色是擁有極大的上下文視窗(Context Window),可以一次讀取整個大型專案的所有程式碼,並支援多模態輸入。
- Cursor CLI:雖然 Cursor 以 IDE 聞名,但其 CLI 版本在工具編排(Tool Orchestration)上非常流暢,適合追求快速迭代的開發者。
- GitHub Copilot CLI:GitHub 官方提供的工具(透過
gh copilot使用)。它主要功能是「翻譯」指令,當你忘記 git 或 docker 的複雜參數時,它可以幫你寫好指令並解釋其意義。 - Ollama:如果你想在本地端(Offline)執行 AI,Ollama 是首選。它讓你在終端機就能輕鬆下載並執行各種開源模型(如 Llama 3, Mistral, Gemma 等)。
語意切割 vs 靜音偵測
- 靜音偵測(silencedetect): 僅判斷聲音能量高低,容易誤留呼吸聲、笑聲或環境雜訊,無法判斷語句邊界。
- SRT 字幕辨識: 判斷「人類說話的意義」,能確保剪輯出的片段具備完整語意。
- 最佳策略: 以 SRT 作為主判斷基準,輔以靜音偵測做品質檢查。
FFmpeg 音訊優化技巧
- 音量調整: 使用
loudnorm過濾器可自動進行音量標準化,讓小聲變清晰、大聲不破音。 - 人聲增強: 透過
highpass=f=80濾除低頻噪音(如冷氣聲),並用equalizer提升 3000Hz 頻段強化清晰度。 - 去噪處理:
afftdn能智慧去除背景底噪,agate則可在沒人講話時自動關閉音量。 - 環境感: 加入微小的
aecho(如 40ms)能模擬錄音室空間感,讓聲音聽起來更厚實。
解決 Whisper 辨識異常
- 幻覺與長片段問題: 若模型在空白處亂寫或時間軸拉太長,應縮短
min_silence_duration_ms(如 500ms)並關閉condition_on_previous_text。 - 強制切分: 設定
max_speech_duration_s(如 15 秒)限制單一片段長度,避免多句話被擠在同一個時間戳。 - 效率提升: 使用
faster-whisper並配合 VAD(語音活動檢測)進行平行處理,速度比原版快 4-5 倍。 - 增加簡體轉繁體字,避免whisper 誤判。
- 由於模型產生的 segment 不等於「一句話」,最穩定的做法是在程式碼中加入後處理邏輯:設定每行最大字數(如 22 字),若超長則平均分配時間點並換行。
YouTube: https://youtu.be/FNh-PhIEBPY
使用情境
這支腳本特別適合以下場景:
- 教學影片只保留講話段落
- 訪談或會議影片去除空白等待時間
- Podcast 錄影自動裁切發言片段
- AI 轉錄後,直接用字幕反推影片剪輯
你只需要:
- 一個影片檔(mp4 / mkv / mov…)
- 運行 ffmpeg + whisper 的電腦環境. (Mac / Linux / Windows)
- max 的腳本. (選配)
max 的腳本下載:
https://github.com/max32002/srt-video-cutter/
環境與套件需求
在開始之前,請確認以下環境已準備好:
- Python 3.8+
- 系統已安裝
ffmpeg,openai-whisper - Python 套件:
pip install ffmpeg-python pysrt fastapi uvicorn python-multipart jinja2 openai-whisper setuptools-rust faster-whisper opencc-python-reimplemented
其中:
- ffmpeg-python:FFmpeg 的 Python 封裝,用來描述影片處理流程
- pysrt:專門解析
.srt字幕檔的工具 - whisper:聲音轉
.srt字幕檔的工具 - opencc:簡體字轉繁體字
腳本整體流程說明
video_cutter.py 程式的邏輯可以拆成 6 個步驟:
- 讀取並檢查影片與字幕檔是否存在
- 解析 SRT,取得每一段字幕的開始與結束時間
- 對影片與音訊分別做
trim - 重設時間軸(PTS),避免剪接錯位
- 將所有片段依序 concat
- 輸出成一支新的影片檔
來源檔案轉換為單聲道 MP3 (16kHz), 是透過 ffmpeg 指令
ffmpeg -i input.mp3 -ar 16000 -ac 1 -ab 16k output.mp3生成字幕, 是透過 whisper 指令
whisper audio.mp3 --language=zh --device=cpu --model=turbo說明:直接執行 run.bat 無法下載 whisper 的模型檔案, 請透過上面指令手動下載 turbo 模型.
如果你遇到下列錯誤訊息, 就是需要手動執行一次 whisper 指令:
--- 開始處理: c:\max\woman.mp3 (Device: cpu, Model: turbo) ---
Warning: You are sending unauthenticated requests to the HF Hub. Please set a HF_TOKEN to enable higher rate limits and faster downloads.
C:\\Programs\Python\Python312\Lib\site-packages\huggingface_hub\file_download.py:138: UserWarning: `huggingface_hub` cache-system uses symlinks by default to efficiently store duplicated files but your machine does not support them
To support symlinks on Windows, you either need to activate Developer Mode or to run Python as an administrator. In order to activate developer mode, see this article: https://docs.microsoft.com/en-us/windows/apps/get-started/enable-your-device-for-development
warnings.warn(message)
Faster-Whisper 錯誤: [WinError 1314] 用戶端沒有這項特殊權限。
安裝的教學, 參考: https://max-everyday.com/2025/12/whisper-python/
指令的使用方式
python video_cutter.py input.mp4video_cutter.py 實作的細節
不知道也沒差,建議直接略過這個區塊
1️⃣ 合併過短字幕
- 設定最小片段長度(例如 0.4 秒)
- 若某段太短,嘗試與前一段合併
- 合併條件:時間間隔不超過指定閾值(例如 0.3 秒)
2️⃣ 前後 padding
- 對每段字幕加上前後緩衝(例如 ±0.15 秒)
- 自動 clamp 在 0 與影片總長度之間
- padding 在「合併後」才套用,避免重疊錯亂
3️⃣ 靜音偵測(輔助條件)
- 使用 ffmpeg 的
silencedetect - 先跑一次分析音訊,取得靜音區段
- 若字幕區間完全落在靜音內 → 捨棄
- 若只部分靜音 → 保留(字幕仍有意義)
使用「靜音偵測」就不需要輸入 srt 字幕檔了嗎?
這是一個非常關鍵、而且問得很精準的問題。結論先給你,再把背後的設計邏輯一次說清楚。
結論一句話:
只用「靜音偵測」可以剪影片,但「不能等價取代 SRT(Whisper)」;兩者的角色本質不同。
先把兩者在「影片自動切割」中的定位講清楚。
Whisper 產生的 SRT,本質上是在回答一個問題:
「這段時間,人類在說『有意義的話』嗎?」
而靜音偵測(silencedetect),回答的是另一個問題:
「這段時間,聲音能量是否低於某個門檻?」
這兩件事不是同一件事,也不互為子集。
一、只用靜音偵測,不用 SRT,會發生什麼事?
你可以完全不用 SRT,只靠靜音來切,例如:
- 偵測所有非靜音區間
- 每段非靜音就是一個剪輯段
這在「技術上」完全可行,而且程式還更簡單。
但實際效果會有幾個不可避免的問題:
- 會保留大量「沒有語意價值」的聲音
例如:- 呼吸聲
- 笑一下
- 背景音樂
- 咳嗽
- 嘆氣、嗯、啊
- 無法判斷「語句邊界」
一句話中間短暫停頓 0.2 秒,
靜音偵測可能直接把它切成兩段。 - 對內容型影片不友善
像是:- 教學影片
- 訪談
- Podcast
- YouTube talking head
不是「有聲音就留」。
因此:
只靠靜音偵測,剪出來的是「聲音片段」,不是「語意片段」。
二、那是否代表一定需要 SRT(Whisper)?
這要看你的「剪輯目標」。
可以這樣判斷:
如果你的目標是這種 → 可以不需要 SRT
- 去掉完全沒聲音的空白
- 快速裁掉長時間靜默
- 監控錄音品質
- Podcast 粗剪(人工後製)
如果你的目標是這種 → SRT 幾乎是必要的
- 依照「一句話」切段
- 產生短影音(Reels / Shorts)
- 自動章節
- 後續做摘要、關鍵句擷取、翻譯
你目前描述的用途是:
SRT 主要是透過 whisper 來產生,目的是利用 SRT 字幕自動切割影片
這個用途,本質上就是 語意導向切割,
所以 SRT 不是多餘的,而是核心訊號來源。
三、正確的工程思路:不是「二選一」,而是「主從關係」
在成熟的系統裡,設計通常是這樣:
Whisper / SRT:主判斷(語意)
靜音偵測:輔助過濾(聲學)
實務上最穩定的策略是:
- 用 SRT 決定「候選剪輯區間」
- 用靜音偵測做「品質檢查」
- 字幕區間內如果 90% 都是靜音 → 丟棄
- 字幕前後有長靜音 → 裁掉
- 最後再補 padding,讓語音自然進出
也就是你目前優化方向中,最合理的一條路。
四、什麼情況下「可以完全不要 SRT」?
只有在以下情境,我會建議你拿掉 SRT:
- 你已經不在乎「說了什麼」
- 你只想保留「有聲音的地方」
- 或你後面還會人工看一遍再修
例如:
- 監控錄影
- 課堂錄音粗剪
- 音檔清理工具
一旦你的目標是「自動產出可直接發布的內容」,
SRT(Whisper)就不是 optional,而是語意層的 ground truth。
ffmpeg 增加影片的音量
要讓音量達到最大但不破音,最保險的做法是先進行音量標準化。這通常需要跑兩次指令,或者用一個比較聰明的過濾器。
使用簡單的標準化
這個指令會自動搜尋音軌中的最高點,並將其提升到 0dB,也就是不失真的最大極限。這對於聲音太小的檔案非常有用。
ffmpeg -i input.mp4 -af "loudnorm=I=-16:TP=-1.5:LRA=11" -c:v copy output.mp4兩步驟自動偵測
如果你想更精確地提升,可以先執行 volumedetect 找出最大增益。這個指令不會輸出新檔案,只是幫你計算數據。
ffmpeg -i input.mp4 -af volumedetect -f null /dev/null在 Windows 中,我們把空輸出指向 NUL。
ffmpeg -i input.mp4 -af volumedetect -f null NUL執行後在輸出的文字裡找 max_volume。如果顯示為 -6.0dB,代表你還有 6dB 的增加空間。接著再手動輸入增加的數值。
ffmpeg -i input.mp4 -af "volume=6dB" -c:v copy output.mp4分析偵測結果
你的 max_volume 是 -1.2 dB。這代表這段影片中最大聲的地方,距離數位音訊的極限(0 dB)只剩下 1.2 dB 的空間。如果你的目標是單純增加音量且不想讓聲音破掉,你最多只能增加 1.2 dB。
執行調整指令
如果你確定要調到極限(也就是讓最大聲的地方剛好達到 0 dB),請在 Windows CMD 執行以下指令:
ffmpeg -i input.mp4 -af "volume=1.2dB" -c:v copy output.mp4關於音量的建議
雖然最大值接近極限,但你的 mean_volume(平均音量)只有 -25.0 dB。這表示這段影片大部分時間聲音其實很小,只有少數幾個地方突然很大聲。
如果你覺得聽起來還是太小聲,單純調高 volume 可能會導致大聲的地方破音。這種情況建議改用前面提到的 loudnorm 指令,它會壓縮大聲的部分並提升小聲的部分,讓整體的聽感變大。
ffmpeg -i input.mp4 -af "loudnorm" -c:v copy output_norm.mp4為什麼直接使用 loudnorm 過濾器處理過的檔案, 再使用偵測可增加的音量空間, max_volumn 反而下降?
這是一個很專業的觀察。直接使用 loudnorm 後 max_volume 反而下降,主要是因為這個過濾器的工作邏輯與單純調整增益(Gain)完全不同。
動態範圍壓縮的影響
loudnorm 是一種智慧型的音量標準化工具。它不只是把聲音推大,還會同時檢查聲音的動態範圍。為了讓整體聽感達到目標的響度(預設通常是 -16 LUFS),它會壓縮聲音的高峰。當它偵測到原始音軌中某些瞬間的峰值太高時,為了符合整體的響度標準,它會主動把這些高峰壓低,導致你看到的 max_volume 數值從 -1.2 dB 往下降。
防止數位失真的保護機制
loudnorm 內建了一個參數叫作 TP(True Peak),預設值通常是 -2.0 dB。這是一個安全閥,目的是確保處理後的聲音在任何播放設備上都不會產生數位破音。因為你原本的 max_volume 是 -1.2 dB,已經比這個安全標準還要大聲,所以 loudnorm 會強制把它壓回到 -2.0 dB 左右或更低,這就是為什麼偵測結果數值會變小的原因。
響度與峰值的差異
在音訊處理中,大聲不代表峰值高。max_volume 只代表影片中最響的那一個瞬間,而 loudnorm 關注的是整段影片聽起來的平均感覺。雖然峰值下降了,但因為它把原本微弱的聲音補償上來了,實際聽起來的感覺反而會比原本更清晰、更大聲。
你的測試結果驗證
這證明了 loudnorm 正在正確執行它的任務:它放棄了極少數的最高點空間,換取了整段音軌更一致、更飽滿的聽感。如果你希望處理後的 max_volume 更接近 0 dB,可以在指令中手動加上 TP 參數:
ffmpeg -i input.mp4 -af "loudnorm=TP=-0.1" -c:v copy output.mp4這樣雖然峰值會上升,但通常不建議這麼做,因為留一點預留空間(Headroom)對音質比較好。
產生 Echo 回音音效
ffmpeg 使用 aecho 濾鏡來製作回音。你需要設定輸入增益、輸出增益、延遲時間以及衰減比例。
ffmpeg -i input.mp4 -af "aecho=0.8:0.8:1000:0.5" -c:v copy output.mp4這行指令的參數意義如下:
- 0.8:原始聲音的音量。
- 0.8:回音的音量。
- 1000:延遲時間(毫秒),1000 代表 1 秒。
- 0.5:每次回音衰減的比例。
調整 EQ 均衡器
如果你想調整高低音,最直覺的是使用 equalizer 濾鏡。你可以針對特定的頻率進行增益或衰減。
例如,如果你想提升 1000Hz 附近的聲音(讓人聲更清晰),增加 6 分貝:
ffmpeg -i input.mp4 -af "equalizer=f=1000:width_type=h:w=200:g=6" -c:v copy output.mp4- f=1000:中心頻率。
- width_type=h:頻寬單位。
- w=200:影響的頻率範圍寬度。
- g=6:增益分貝數。
快速調整高低音 (Bass/Treble)
如果你不想設定複雜的 EQ,可以直接用 bass 或 treble 濾鏡。這對高中生理解音訊調整最簡單。
提升重低音:
ffmpeg -i input.mp4 -af "bass=g=10" -c:v copy output.mp4提升高音:
ffmpeg -i input.mp4 -af "treble=g=8" -c:v copy output.mp4多重濾鏡組合
你可以把音量調整、EQ 和回音全部串在一起使用,中間用逗號隔開即可。
ffmpeg -i input.mp4 -af "volume=1.2,bass=g=5,aecho=0.8:0.5:500:0.3" -c:v copy output.mp4完整的人聲優化指令
這串指令包含了高通濾波、人聲強化和動態門檻去噪。
ffmpeg -i input.mp4 -af "highpass=f=80, lowpass=f=8000, afftdn=nr=10, equalizer=f=3000:width_type=h:w=200:g=3, loudnorm" -c:v copy output.mp4濾鏡參數詳細解說
1. 高通與低通濾波 (highpass/lowpass)
highpass=f=80 會切斷 80Hz 以下的聲音。人聲通常不會低於這個頻率,但冷氣運轉或電流聲的低頻雜訊會被擋掉。lowpass=f=8000 則是過濾掉極高頻的刺耳雜音。
2. 智慧去噪 (afftdn)
afftdn 是 ffmpeg 內建強大的降噪工具。nr=10 代表降噪強度。如果你的背景嘶嘶聲很明顯,可以適度調高這個數值(建議在 10 到 20 之間),但調太高會讓人聲聽起來像在水底下說話。
3. 人聲頻段強化 (equalizer)
equalizer=f=3000:g=3 針對 3000Hz 左右進行微幅增益。這個頻段通常是人聲清晰度的關鍵,稍微拉高能讓講話聲更突出、更有磁性。
4. 終端響度標準化 (loudnorm)
最後放上 loudnorm 是為了確保優化後的聲音音量穩定,不會因為去噪過程讓音量忽大忽小。
進階去噪:使用動態閘門 (agate)
如果你的錄音環境有明顯的間歇性背景噪音(例如翻書聲或細微鍵盤聲),可以加入 agate 濾鏡。它會在沒人講話時自動把音量關到極小。
ffmpeg -i input.mp4 -af "agate=threshold=-30dB:ratio=2, highpass=f=80, afftdn, loudnorm" -c:v copy output.mp4加入一點點空間感(Room Ambience)可以讓人聲聽起來更自然,不會像是在完全真空的密室裡講話。我們可以利用 aecho 來模擬微弱的牆面反射,讓 Podcast 更有專業錄音室的質感。
錄音室空間感指令
這組設定會加入極短的回音,聽覺上不會感覺到有明顯的「回聲」,而是覺得聲音變厚實了。
ffmpeg -i input.mp4 -af "highpass=f=80, afftdn=nr=12, aecho=0.8:0.3:40:0.2, loudnorm" -c:v copy output.mp4參數調整重點
1. 空間感設定 (aecho)
aecho=0.8:0.3:40:0.2 這裡的核心在於 40 毫秒。這是一個非常短的時間,人耳聽不出延遲,只會覺得聲音多了一層包覆感。如果數字調到 500 以上,就會變成像在山洞說話的效果。
2. 去噪強度 (afftdn)
我把 nr 微調到了 12。這在去除 Podcast 背景底噪(如電腦風扇聲)非常有效。如果雜音還是很大,你可以嘗試把這個數值加到 15。
3. 低頻切除 (highpass)
這一步絕對不能省。Podcast 聽眾很多是用耳機收聽,切掉 80Hz 以下的雜訊,能大幅減少聽覺疲勞,讓人聲聽起來很乾淨。
檢查處理後的波形
處理完後,建議你再次使用 volumedetect 檢查。
ffmpeg -i output.mp4 -af volumedetect -f null NUL你會發現 mean_volume(平均音量)應該會提升到 -16dB 附近,這正是目前國際 Podcast 平台的標準響度,聽眾在切換不同節目時,不需要一直手動調整手機音量。
highpass=f=200 與 highpass=f=80 的差異
濾除雜訊的強度
highpass=f=200 會切掉更多聲音。它能有效去掉冷氣運轉、交通工具轟鳴或遠處的低頻噪音。但缺點是它可能會切到男聲的基頻,讓聲音聽起來像透過舊式電話講話,變得很薄。對於 Whisper 來說,這通常不是問題,因為它辨識的是特徵而不是音質。
保留人聲的自然感
highpass=f=80 則溫和得多。它只會切掉人耳幾乎聽不到、但會讓麥克風產生震動的極低頻雜訊。這個設定能保留說話者聲音的厚度與磁性。如果你錄音的環境本來就很安靜,只是想做基本的清理,選 80 比較能維持原音。
針對 Whisper 的實務建議
如果你的錄音環境有明顯的環境低音,或是說話者離麥克風很近產生的噴麥聲(氣流撞擊聲),直接設定 200 會比較保險。Whisper 不需要好聽的低音,它需要的是乾淨的語音邊界。切掉 200Hz 以下的內容,可以讓模型更專注在 1kHz 到 4kHz 這些充滿語意資訊的頻段。
兩者的適用場景
如果你不確定該選哪一個,可以先聽聽看原始檔。如果背景有很重的嗡嗡聲,選 200。如果錄音很乾淨只是想稍微過濾,選 80 或 120 是比較折衷的做法。通常在嘈雜的咖啡廳或戶外錄音,我會建議直接從 200 起跳。
lowpass=f=3000 與 lowpass=f=8000 的差異
lowpass=f=3000 會把 3000Hz 以上的聲音全部切掉。這會讓聲音聽起來悶悶的,像是在隔壁房間說話。絕大多數的漢語或英語元音資訊都在這個範圍內。但要注意的是,像「s」、「f」、「sh」這類高頻的摩擦音,頻率通常在 4000Hz 以上。切得太乾(3000Hz)可能會讓這些齒音變得模糊。
高頻雜訊的過濾
lowpass=f=8000 則寬鬆許多。它能保留大部分的人聲細節,包含那些細微的發音特徵。它主要的功能是過濾掉電子設備的高頻嘶嘶聲、蟬鳴聲或極端尖銳的雜音。對於 Whisper 來說,8000Hz 通常是一個比較安全的平衡點,既能去噪又不會傷到語音特徵。
對 Whisper 的影響
Whisper 在訓練時看過各種品質的音檔。雖然 16kHz 的採樣率最高只能容納 8000Hz 的聲音,但如果你預處理時直接切到 3000Hz,可能會損失掉一些辨識子音的重要資訊。除非背景有非常刺耳的高頻電流聲,否則不建議切到 3000Hz 這麼低。
建議的設定值
如果你發現錄音中有很多噴麥或環境雜音,選 8000Hz 已經足夠應付多數情況。如果環境真的很糟糕,可以嘗試設定在 4000Hz 或 5000Hz 之間,這能保證語音的關鍵摩擦音不會被濾除。通常 3000Hz 是在極端惡劣、滿是高頻干擾時才考慮的最後手段。
套用 loudnorm, 開場的第一句話變的很小聲.
這通常是因為 loudnorm 預設是「單次掃描」(One-pass)模式。在這種模式下,ffmpeg 還沒分析完整段音訊,只能邊走邊猜。當開場的第一句話突然出現時,濾鏡為了保險起見會壓低音量,導致聽起來悶悶的。
解決開場音量過小的問題
要解決這個問題,最專業的做法是提供「預測數據」。你可以手動調整以下細部參數,或是改用兩次掃描模式。
1. 調整目標響度與峰值
你可以透過調整 I(目標響度)和 TP(真峰值)來讓整體聲音更響亮。
ffmpeg -i input.mp4 -af "loudnorm=I=-14:TP=-1.0:LRA=11" -c:v copy output.mp4- I=-14:目標響度。數值越小(如 -12)聲音越大。Podcast 建議在 -16 到 -14 之間。
- TP=-1.0:允許的最高峰值。從預設的 -2.0 改成 -1.0 可以釋放更多音量空間。
2. 關閉線性限制 (measured)
如果你發現第一句話被壓得太厲害,可以嘗試強制設定 measured 參數。但更簡單的方法是調整 LRA(響度範圍)。
LRA=15:增加動態範圍。這會讓大聲與小聲的落差變大,有時候能減緩開場被強行壓低的感覺。
徹底解決方法:兩次掃描 (Two-pass)
這是大部份專業人士的做法。第一次先讓 ffmpeg 記住整段影片的音量特徵,第二次再根據這些數據進行精確調整。這樣濾鏡就不會在開場時「反應過度」。
在 Windows 上手動做兩次掃描比較麻煩,但有一個作弊的方法,就是調大內建的緩衝區。
增加預測緩衝
雖然 ffmpeg 的 loudnorm 主要靠演算法,但你可以嘗試在人聲處理鏈中,先放一個 compand(壓縮器)來預處理,或是直接改用 speechnorm。
如果你堅持用 loudnorm 且不想跑兩次指令,可以試試看這個組合,這對開場壓抑會有改善:
ffmpeg -i input.mp4 -af "loudnorm=I=-16:TP=-1.5:LRA=11:measured_I=-25.0:measured_TP=-1.2:measured_LRA=7.0:measured_thresh=-35.0" -c:v copy output.mp4註:上面的
measured數值是我根據你之前提供的偵測數據填入的。手動餵入這些偵測到的數據,能讓loudnorm在開場時就知道該怎麼處理。
另一個選擇:speechnorm
如果 loudnorm 讓 Podcast 開場聽起來還是很不自然,我強烈建議換成 speechnorm。它是專門為語音設計的,能非常平滑地調整每一句話的音量。
ffmpeg -i input.mp4 -af "speechnorm=e=4:p=0.9" -c:v copy output.mp4你想試試看用 speechnorm 處理的效果嗎?它通常比 loudnorm 更適合解決「第一句話變小聲」的問題。
Whisper 進行語音轉文字(Audio to Text),「將檔案切成小片段」是否比較有效率
關於使用 OpenAI Whisper 進行語音轉文字(Audio to Text),「將檔案切成小片段」是否比較有效率,答案是:是的,通常比較有效率,但前提是「切分的方式要正確」。
如果只是單純為了速度而粗暴地切割檔案(例如固定每 60 秒切一刀),可能會導致辨識準確度下降。
以下為您詳細分析為什麼要切分、以及如何切分才是最好的策略:
1. 為什麼切成小檔案比較有效率?(優點)
- 平行處理(Parallel Processing / Batching):
這是最大的優勢。如果您將一個 1 小時的檔案切成 60 個 1 分鐘的檔案,您可以利用 GPU 的「批次處理(Batching)」功能,同時辨識多個片段。這比依序讀取一個長檔案要快得多。 - 記憶體管理(VRAM Usage):
雖然 Whisper 的記憶體使用量主要取決於模型大小(如 large-v3),但處理極長的音訊檔案有時會導致記憶體溢出(OOM)或處理緩衝區過大的問題。切分檔案可以讓記憶體負載更穩定。 - 避免累積錯誤(Hallucination Loop):
Whisper 在遇到長時間的靜音或背景噪音時,有時會產生「幻覺」(Hallucinations),例如不斷重複同一句話。切分檔案可以強制模型在每個新片段「重置」狀態,減少這種錯誤無限延續的風險。 - 容錯率:
如果處理長檔案到 99% 時程式崩潰,您可能要從頭再來;如果是小檔案,您只需要重新跑失敗的那一小段。
2. 切分檔案的潛在風險(缺點)
- 上下文遺失(Context Loss):
Whisper 是利用上下文來判斷同音異字的。如果您剛好切在一個句子的中間,模型會失去前後文,導致誤判。
例子: 如果您在「人工智…」切斷,下一段是「…能」,模型可能分別辨識成錯誤的字,而不是完整的「人工智慧」。
- 邊界效應:
切分點附近的音訊可能會因為波形被截斷而產生雜音,影響辨識。
3. 如何正確地切分?(最佳實務)
為了兼顧效率與準確率,絕對不要使用「固定時間切割」(例如每 30 秒切一次),建議採用以下策略:
A. 使用 VAD(語音活動檢測)切割
這是最標準的做法。利用 VAD (Voice Activity Detection) 演算法,找出音訊中的「靜音片段」,在說話者停頓換氣的地方進行切割。
- 優點: 確保句子是完整的,不會切斷單字。
- 工具:
pyannote-audio或 Silero VAD。
B. 使用優化過的函式庫(推薦 faster-whisper)
原版的 OpenAI Whisper 程式碼在處理長檔案時速度較慢。目前社群最推薦使用的是 faster-whisper。
- 原理: 它底層使用了 CTranslate2 引擎,比原版快 4-5 倍,並且內建了很好的 VAD 處理邏輯。它會自動在記憶體中幫您做好「切分 -> 批次辨識 -> 合併」的動作,您不需要手動去切實體檔案。
C. 若必須手動切檔 (使用 FFmpeg)
如果您因為某些原因必須手動切檔,請利用 ffmpeg 的 silencedetect 功能來尋找靜音點切割,而不是單純用 -segment_time。
4. 總結比較表
| 處理方式 | 速度效率 | 準確度 | 記憶體消耗 | 建議程度 |
|---|---|---|---|---|
| 單一長檔案 (原版 Whisper) | 低 (依序處理) | 高 (上下文完整) | 高 (可能不穩) | ⭐⭐ |
| 固定時間切割 (如每30秒) | 高 (可平行) | 低 (容易切斷句子) | 低 | ⭐ (不建議) |
| VAD 靜音切割 (手動/程式) | 極高 (可平行) | 高 (保留句子完整) | 低 | ⭐⭐⭐⭐ |
| 使用 faster-whisper | 極高 | 高 | 最佳化 | ⭐⭐⭐⭐⭐ |
Whisper 模型陷入了「幻覺」或「長片段過度延伸」
例如: 一句話占用了 2分鐘.
問題原因與調整建議
這種情況通常不是 VAD 沒運作,而是模型陷入了「幻覺」或「長片段過度延伸」。當語音結尾出現較長的空白,或者背景有極微弱的環境雜音(例如底噪、電扇聲),Whisper 有時會以為這句話還沒結束,硬生生把結束時間往後拉,直到遇到下一個明顯的聲音。
你可以嘗試調整 transcribe 函數中的參數來修正這個現象。
建議修改的參數
在你的程式碼中,找到 model.transcribe 的位置,建議加入以下參數進行微調:
Python
segments, info = model.transcribe(
input_file,
language=language,
vad_filter=True,
# 調整 VAD 參數
vad_parameters=dict(min_silence_duration_ms=1000),
# 控制無聲片段的判斷
no_speech_threshold=0.6,
# 限制沒有聲音時的處理方式
compression_ratio_threshold=2.4
)
修改重點說明
- min_silence_duration_ms: 這是 VAD 判斷「靜音」的門檻。預設通常是 2000ms(2秒),如果你覺得兩分鐘太誇張,可以縮短這個數值(例如 1000 或 500),讓它更敏感地切斷句子。
- no_speech_threshold: 這是模型對「無聲」的信心門檻。提高這個數值(例如 0.6 或 0.7),可以讓模型在不確定有沒有人聲時,更果斷地放棄辨識,避免把底噪硬抓來轉文字。
- compression_ratio_threshold: 當模型開始亂寫、重複字詞或陷入長延時幻覺時,壓縮比通常會飆高。設定這個門檻可以讓模型在發現內容太混亂時,主動切斷該片段。
進階解決方案:強行切斷
如果調整 VAD 參數後效果還是有限,通常是因為錄音環境的底噪被模型誤認為是人聲。你可以試著加入 condition_on_previous_text=False。
這個參數會讓模型在處理下一段時,不參考前一段的內容。雖然可能會降低語意連貫性,但能有效防止「上一句的幻覺」一直帶到下一句,導致時間軸無限延伸。
整合參數後的程式碼
我把建議的參數直接加入 model.transcribe 裡。這樣可以讓 VAD 更敏銳,並減少模型在空白處「硬湊」時間的問題。
Python
import os
from contextlib import ExitStack
def run_faster_whisper_task(input_file: str, language: str, model_size: str, device: str, output_formats: List[str]):
try:
print(f"--- 開始處理: {input_file} (Device: {device}, Model: {model_size}) ---")
compute_type = "float16" if device == "cuda" else "int8"
model = WhisperModel(model_size, device=device, compute_type=compute_type)
# 加入優化參數解決長延遲問題
segments, info = model.transcribe(
input_file,
language=language,
vad_filter=True,
# 只要靜音超過 1 秒就切斷,不讓它連在一起
vad_parameters=dict(min_silence_duration_ms=1000),
# 提高對無聲的判定標準,避免抓到底噪
no_speech_threshold=0.6,
# 防止上一句的內容影響下一句,減少幻覺
condition_on_previous_text=False
)
base_name = os.path.splitext(input_file)[0]
print(f"偵測到語言: {info.language} (信心度: {info.language_probability})")
with ExitStack() as stack:
f_srt = None
f_txt = None
if "srt" in output_formats or "all" in output_formats:
srt_path = f"{base_name}.srt"
f_srt = stack.enter_context(open(srt_path, "w", encoding="utf-8"))
if "txt" in output_formats or "all" in output_formats:
txt_path = f"{base_name}.txt"
f_txt = stack.enter_context(open(txt_path, "w", encoding="utf-8"))
for i, segment in enumerate(segments, start=1):
start_time = format_timestamp(segment.start)
end_time = format_timestamp(segment.end)
text = segment.text.strip()
if f_srt:
f_srt.write(f"{i}\n")
f_srt.write(f"{start_time} --> {end_time}\n")
f_srt.write(f"{text}\n\n")
f_srt.flush()
if f_txt:
f_txt.write(f"{text}\n")
f_txt.flush()
print(f"[{start_time} -> {end_time}] {text}")
print(f"--- 處理完成 ---")
except Exception as e:
print(f"Faster-Whisper 執行錯誤: {e}")
調整說明
這段程式碼主要做了兩件事。第一是把 min_silence_duration_ms 縮短,讓 VAD 看到超過 1 秒的空白就強制收尾,不讓它繼續延伸。
第二是關掉了 condition_on_previous_text。這很重要,因為有時候模型會因為上一句還沒講完的錯覺,把後面的空白時間全部吃掉。關掉它後,每一段辨識都會比較獨立,時間軸也會精準很多。
最後也保留了你要的「不產生多餘檔案」的邏輯。如果跑完後發現時間軸還是偏長,可以再把 no_speech_threshold 往上調。
解決多句話合併的方法
解決多句話合併的方法
多句話被擠在同一個時間軸,通常是因為 Whisper 的 max_initial_timestamp 或內部的 word_timestamps 機制覺得這些句子之間停頓不夠明顯。要解決這個問題,除了調整 VAD 參數外,最有效的方法是加入「時間戳限制」與「強制切分」參數。
建議調整的參數
請在 model.transcribe 中加入 max_new_tokens 與 chunk_length 相關的限制:
Python
segments, info = model.transcribe(
input_file,
language=language,
vad_filter=True,
vad_parameters=dict(min_silence_duration_ms=500), # 縮短靜音判定,強制切分
# 限制一個片段的最長秒數,避免過長合併
clip_timestamps=[0],
# 加入以下關鍵參數
max_initial_timestamp=1.0,
word_timestamps=False, # 如果不需要逐字時間戳,關閉它有助於穩定句子邊界
# 這是核心:限制模型一次處理的長度
initial_prompt="以下是逐句對話。", # 給模型提示,讓它傾向於斷句
)
修改重點說明
- 縮短 min_silence_duration_ms: 將 1000ms 改為 500ms(0.5秒)。只要講話稍微停頓,VAD 就會把這段切開,不會讓它變成一大串。
- max_initial_timestamp: 限制模型在搜尋聲音起點時的範圍,這能強迫模型更頻繁地重新對齊時間軸。
- initial_prompt: 這是一個小技巧。在提示詞裡加入標點符號或說明「這是逐句轉錄」,模型在輸出時會更傾向於加上標點並斷句,而不是吐出一長串沒有停頓的文字。
- 語音長度限制: 如果你的音檔底噪真的很大,導致 VAD 失靈,可以在程式碼層面檢查
segment.end - segment.start。如果差值超過 15 秒,就代表這一句太長了,這通常是模型卡住的徵兆。
在 faster-whisper 中,雖然參數名稱和原始的 OpenAI Whisper 略有不同,但我們可以透過 vad_parameters 中的 max_speech_duration_s 來限制每個片段的最長秒數。
另外,我們可以用 initial_prompt 強制模型在語氣停頓處斷句。
加入長度限制後的程式碼
Python
segments, info = model.transcribe(
input_file,
language=language,
vad_filter=True,
# vad_parameters 是控制切分長度的關鍵
vad_parameters=dict(
min_silence_duration_ms=500, # 只要停頓 0.5 秒就切斷
max_speech_duration_s=15 # 強制每一段話最長不能超過 15 秒
),
# 限制模型一次生成的字數,避免一段話塞進太多內容
# beam_size 設小一點有助於減少模型過度延伸的幻覺
beam_size=5,
# 給模型暗示,讓它知道要分句
initial_prompt=",。!?",
# 關閉前文關聯,防止模型為了連貫性把句子硬湊在一起
condition_on_previous_text=False
)
參數修改說明
- max_speech_duration_s: 這是最直接的解藥。我把它設為 15 秒,這代表 VAD 只要偵測到語音長度快到 15 秒,就會強行切斷並產生一個時間戳。這能解決你看到那種一整分鐘都沒斷句的問題。
- min_silence_duration_ms: 調降到 500ms(0.5秒)。這會讓程式對說話者的換氣、停頓更敏感,進而增加斷句頻率。
- initial_prompt: 我直接給它標點符號。這會引導模型在生成文字時,主動在該斷句的地方放上標點,這在處理「然後」、「接著」這種口頭禪時效果很好。
- beam_size: 雖然這主要影響準確度,但設在 5 左右通常是速度與穩定度的平衡點,能減少模型胡言亂語的機率。
你可以先試試看這組設定,15 秒的強制限制應該能馬上解決多句合併的問題。
為什麼已經知道是不同句話, 卻還是要合併句子
這是一個常見的技術陷阱。之所以會出現「明明語氣斷了,時間軸卻連在一起」,主要有三個原因:
為什麼會被合併
- VAD 沒抓到夠長的靜音:Whisper 預設要看到一段明顯的「無聲區」才會切段。如果說話者語速快,或環境底噪(如風扇、電腦運流聲)太重,VAD 會以為中間那幾毫秒的停頓只是換氣,不是句子結束。
- 模型試圖補完語意:Whisper 的特色是它會「預測」下一句。當它聽到「然後」、「接著」這種連接詞,它會覺得這句話還沒講完,為了語句通順,它會把後面的內容強行拉進同一個時間戳裡。
- 預設的最短片段限制:模型為了避免產生太多只有 1 秒的碎片段,有時會自動把相近的聲音合併,結果反而造成了你看到的 15 秒長句。
解決方案:強制切分與語境分離
要修正這個問題,必須在 model.transcribe 裡加上更嚴格的參數。請將這段整合進你的程式中:
Python
segments, info = model.transcribe(
input_file,
language=language,
vad_filter=True,
vad_parameters=dict(
min_silence_duration_ms=400, # 更敏感,停頓 0.4 秒就切斷
max_speech_duration_s=10, # 強制每段最長 10 秒,解決長句問題
speech_pad_ms=200 # 減少片段前后的緩衝音
),
# 這是關鍵:關閉前文關聯
condition_on_previous_text=False,
# 加入提示詞,強迫模型在看到連接詞時斷開
initial_prompt="。,接著。然後。",
# 提高對無聲的判斷,不要讓底噪把兩句話連起來
no_speech_threshold=0.6
)
修改後的變化
這組參數會讓 VAD 變得非常「沒耐心」。只要你稍微停頓 0.4 秒,它就會強行結束這一局。
加上 condition_on_previous_text=False 後,模型就不會因為看到「然後」就想去接前面的話。它會把每一段都當作全新的開始,這樣時間軸就會被切得很碎、很精準。
如果修改後發現句子斷得太細,可以再把 min_silence_duration_ms 稍微往上調。
需要我幫你把這組「嚴格斷句版」參數放進完整的函數程式碼中嗎?
還是 chatGPT 解決問題能力較強,
你這份設定其實已經接近 faster-whisper 能做到的極限切分了,多句字幕被合併,原因主要不是「bug」,而是 Whisper 本身的語言模型行為 + VAD 與 segment 定義方式。下面我直接用「為什麼會合併 → 怎麼徹底解」的角度來說,並給你可直接套用的修正方案。
先說結論:
只靠 transcribe 參數,無法 100% 防止多句合併在同一個 segment。
真正穩定的解法是 「模型切段 + 後處理再切一次字幕」。
為什麼你現在的設定還是會合併?
即使你已經做了這些正確的事:
condition_on_previous_text=Falsevad_filter=True- 縮短
min_silence_duration_ms - 限制
max_speech_duration_s - 設小
beam_size - 提高
no_speech_threshold
但 Whisper 的 segment 不是「一句話」概念,而是「語音連續區間」:
- 只要中間沒有被 VAD 判定為「明確靜音」
- 或模型認為語意連續(尤其是中文)
- 就會把「多句話」吐在 同一個
segment.text
👉 所以你現在看到的是「一個 segment 裡面有好幾句話」
正確做法:保留 Whisper segment,但自己再切字幕
核心策略
- 讓 Whisper 只負責「時間區段」
- 字幕斷句交給你自己(用標點 / 長度 / 停頓)
這是專業字幕系統(YouTube、Netflix pipeline)實際用的做法。
解法一(強烈推薦):依標點再切 SRT(最穩)
新增一個「字幕斷句函式」
import re
def split_text_to_sentences(text):
# 中文 + 英文常見斷句符號
pattern = r'(?<=[。!?!?;;])'
parts = re.split(pattern, text)
return [p.strip() for p in parts if p.strip()]
修改你原本的 for loop(關鍵)
srt_index = 1
for segment in segments:
start = segment.start
end = segment.end
text = segment.text.strip()
sentences = split_text_to_sentences(text)
if len(sentences) == 1:
# 原本行為
if f_srt:
f_srt.write(f"{srt_index}\n")
f_srt.write(f"{format_timestamp(start)} --> {format_timestamp(end)}\n")
f_srt.write(f"{sentences[0]}\n\n")
srt_index += 1
continue
# 多句 → 平均切時間
duration = end - start
per_sentence = duration / len(sentences)
for idx, sentence in enumerate(sentences):
s = start + idx * per_sentence
e = s + per_sentence
if f_srt:
f_srt.write(f"{srt_index}\n")
f_srt.write(f"{format_timestamp(s)} --> {format_timestamp(e)}\n")
f_srt.write(f"{sentence}\n\n")
srt_index += 1
效果
- 一個 Whisper segment → 多個 SRT 條目
- 時間仍然合理
- 字幕不再塞成一大句
解法二(進階):限制每行字數(更像專業字幕)
你可以加上「字幕長度限制」,例如 20~25 字:
def split_by_length(text, max_len=22):
result = []
buf = ""
for ch in text:
buf += ch
if len(buf) >= max_len:
result.append(buf)
buf = ""
if buf:
result.append(buf)
return result
可以先「標點切 → 再長度切」。
你現在這些參數,哪些是「有效的」?
✔ 保留(做得對):
condition_on_previous_text=Falsevad_filter=Truemin_silence_duration_ms=300max_speech_duration_sbeam_size=5
⚠️ 影響有限:
initial_promptclip_timestampsmax_initial_timestamp
❌ 無法根治的:
- 單靠 VAD 期待「一句一段」
最佳實務建議(總結)
一句話版本:
Whisper 負責聽,字幕斷句要自己來。
你的 pipeline 建議是:
- faster-whisper:
- 穩定切出時間 segment
- Python 後處理:
- 依「標點 / 長度」再切字幕
- 輸出 SRT
這樣你會得到:
- 不合併句子
- 時間合理
- 可控字幕品質
- 不依賴模型幻覺行為
下面是直接可用的「production 等級 SRT pipeline」,在你原本程式基礎上完成這些事:
- Whisper 只負責時間段(segment)
- 字幕後處理再斷句(標點 → 長度)
- 每個 SRT 最多 2 行
- 每行最多 N 個字(可調)
- 時間合理平均分配
- 不再出現多句塞同一條字幕
你可以整段直接取代原本的 function。
核心字幕切分工具(production 用)
import os
import re
from contextlib import ExitStack
from typing import List
from faster_whisper import WhisperModel
斷句:先標點,再長度
def split_sentences(text: str):
pattern = r'(?<=[。!?!?;;])'
parts = re.split(pattern, text)
return [p.strip() for p in parts if p.strip()]
控制每行長度
def split_by_length(text: str, max_len: int):
lines = []
buf = ""
for ch in text:
buf += ch
if len(buf) >= max_len:
lines.append(buf)
buf = ""
if buf:
lines.append(buf)
return lines
合成「最多 2 行」字幕 block
def build_subtitle_blocks(text: str, max_line_len=22, max_lines=2):
sentences = split_sentences(text)
blocks = []
for sent in sentences:
lines = split_by_length(sent, max_line_len)
for i in range(0, len(lines), max_lines):
block = lines[i:i + max_lines]
blocks.append("\n".join(block))
return blocks
最終版:production SRT pipeline
def run_faster_whisper_task(
input_file: str,
language: str,
model_size: str,
device: str,
output_formats: List[str],
max_line_len: int = 22
):
try:
print(f"--- 開始處理: {input_file} ---")
compute_type = "float16" if device == "cuda" else "int8"
model = WhisperModel(model_size, device=device, compute_type=compute_type)
segments, info = model.transcribe(
input_file,
language=language,
vad_filter=True,
condition_on_previous_text=False,
vad_parameters=dict(
min_silence_duration_ms=300,
max_speech_duration_s=4,
speech_pad_ms=200,
),
beam_size=5,
no_speech_threshold=0.6,
)
base_name = os.path.splitext(input_file)[0]
with ExitStack() as stack:
f_srt = None
f_txt = None
if "srt" in output_formats or "all" in output_formats:
f_srt = stack.enter_context(
open(f"{base_name}.srt", "w", encoding="utf-8")
)
if "txt" in output_formats or "all" in output_formats:
f_txt = stack.enter_context(
open(f"{base_name}.txt", "w", encoding="utf-8")
)
srt_index = 1
for segment in segments:
start = segment.start
end = segment.end
text = segment.text.strip()
if not text:
continue
blocks = build_subtitle_blocks(
text,
max_line_len=max_line_len,
max_lines=2
)
duration = end - start
per_block = duration / len(blocks)
for i, block in enumerate(blocks):
s = start + i * per_block
e = s + per_block
if f_srt:
f_srt.write(f"{srt_index}\n")
f_srt.write(
f"{format_timestamp(s)} --> {format_timestamp(e)}\n"
)
f_srt.write(f"{block}\n\n")
if f_txt:
f_txt.write(block.replace("\n", " ") + "\n")
print(f"[{format_timestamp(s)} -> {format_timestamp(e)}]")
print(block)
srt_index += 1
print(f"--- 處理完成 ({info.language}, {info.language_probability:.2f}) ---")
except Exception as e:
print(f"Faster-Whisper 錯誤: {e}")
參數調整建議
你的設定中 max_speech_duration_s=1 數值過小。這會強制 VAD 每秒鐘就切斷一次。當語音被切得太碎,模型反而容易因為上下文不足而產生幻覺,或是把零碎的聲音補償成重複的文字。建議將這個值放寬到 15 到 20 左右。
目前的字幕出現長達 30 秒的區間,通常是因為 VAD 沒有成功切斷聲音。模型認為這段時間內一直有人在說話。這可能與 min_silence_duration_ms 太短有關。
您可以嘗試以下參數組合:
segments, info = model.transcribe(
input_file,
language=language,
vad_filter=True,
condition_on_previous_text=False,
vad_parameters=dict(
min_silence_duration_ms=500,
max_speech_duration_s=20,
speech_pad_ms=400
),
beam_size=5,
initial_prompt="繁體中文字幕。",
no_speech_threshold=0.6,
log_prob_threshold=-1.0,
compression_ratio_threshold=2.4
)
關鍵調整說明
min_silence_duration_ms 增加到 500 毫秒。這樣模型比較能識別出正常的說話停頓。太短的設定會讓環境噪音干擾判定。
speech_pad_ms 增加到 400 毫秒。這會在切分片段的前後多留一點空間。這能幫助模型完整辨識字首與字尾,減少因為聲音被截斷導致的重複亂碼。
加入 initial_prompt。指定為繁體中文可以導正模型的語氣。這能有效減少出現奇怪贅字或簡繁混雜的機率。
調整 compression_ratio_threshold。如果模型輸出的內容重複率太高,這個參數會觸發重新辨識。這對解決你提到的重複文字問題很有幫助。
python opencc 的 s2t 與 s2tw 差異
OpenCC 是一個很方便的簡繁轉換工具。s2t 與 s2tw 看起來很像,但處理邏輯有明顯區別。這對寫程式或處理文字檔的人來說,選錯轉換模式會讓結果變得很奇怪。
核心轉換邏輯的差異
s2t 的全稱是 Simplified Chinese to Traditional Chinese。它只做字對字的轉換。也就是把簡體字直接換成對應的正體字。這種模式不考慮各地區的用詞習慣。它最適合用在想保留原始語句,只需要更換字體形狀的場景。
s2tw 則是 Simplified Chinese to Traditional Chinese (Taiwan Standard)。它除了換字,還會加入台灣的字形標準。它處理的是字形上的微調,確保轉換後的文字符合台灣教育部門定義的標準字體。
詞彙轉換的層次
雖然 s2tw 處理了台灣字形,但它不一定會處理詞彙轉換。在 OpenCC 的配置中,如果你需要把簡體的計算機換成台灣常用的電腦,通常要使用的是 s2twp。那個 p 代表的是 Phrases,也就是詞彙修正。
單純的 s2t 轉換後,你的文章看起來會像是一個用簡體邏輯寫成的繁體文章。讀起來會有一種違和感。如果你的目標讀者是台灣人,s2tw 或 s2twp 會是比較好的選擇。
實際應用建議
如果你是要開發給台灣用戶使用的 App 或網站,建議選擇 s2twp。這樣不只字形正確,連軟體、內存這種詞彙都能自動轉換成軟體、記憶體。這能大幅提升用戶的閱讀體驗。
缺點也很明顯,完全無法使用大陸的用詞,會被強制轉成台灣用詞,但台灣明明可以用腳本,s2twp 會硬把腳本改成指令碼…, 實在很無言.
實際測試, s2hk 似乎比較好用.
- 原始文字:
通过内存清理软件,可以提高计算机的速度。
台灣, 一台車, 芯片, 腳本, 脚本, 指令码, 指令碼, 软体, 軟體。土豆, 信息,
水平高清发现太后的头发后面有干的长发 - s2t 模式:
通過內存清理軟件,可以提高計算機的速度。
臺灣, 一臺車, 芯片, 腳本, 腳本, 指令碼, 指令碼, 軟體, 軟體。土豆, 信息,
水平高清發現太后的頭髮後面有乾的長髮 - s2tw 模式:
通過內存清理軟件,可以提高計算機的速度。
臺灣, 一臺車, 芯片, 腳本, 腳本, 指令碼, 指令碼, 軟體, 軟體。土豆, 信息,
水平高清發現太后的頭髮後面有乾的長髮 - s2twp 模式:
透過記憶體清理軟體,可以提高計算機的速度。臺灣, 一臺車, 晶片, 指令碼, 指令碼, 指令碼, 指令碼, 軟體, 軟體。土豆, 資訊, 水平高畫質發現太后的頭髮後面有乾的長髮 - s2hk 模式:
通過內存清理軟件,可以提高計算機的速度。
台灣, 一台車, 芯片, 腳本, 腳本, 指令碼, 指令碼, 軟體, 軟體。土豆, 信息,
水平高清發現太后的頭髮後面有乾的長髮


