沒想到「異體字」離我們的生活這麼近,冰淇淋的「淋」和姓氏「林」都有異體字。
前陣子隨手修改了一下Google和Adobe分享的字型檔案,因為Max完全不懂字體相關的知識,把字型檔案解開後,打包不回去。Google查了半天,也看不懂,亂給設定值也失敗,山不轉路轉,那就用其他替代解法吧。
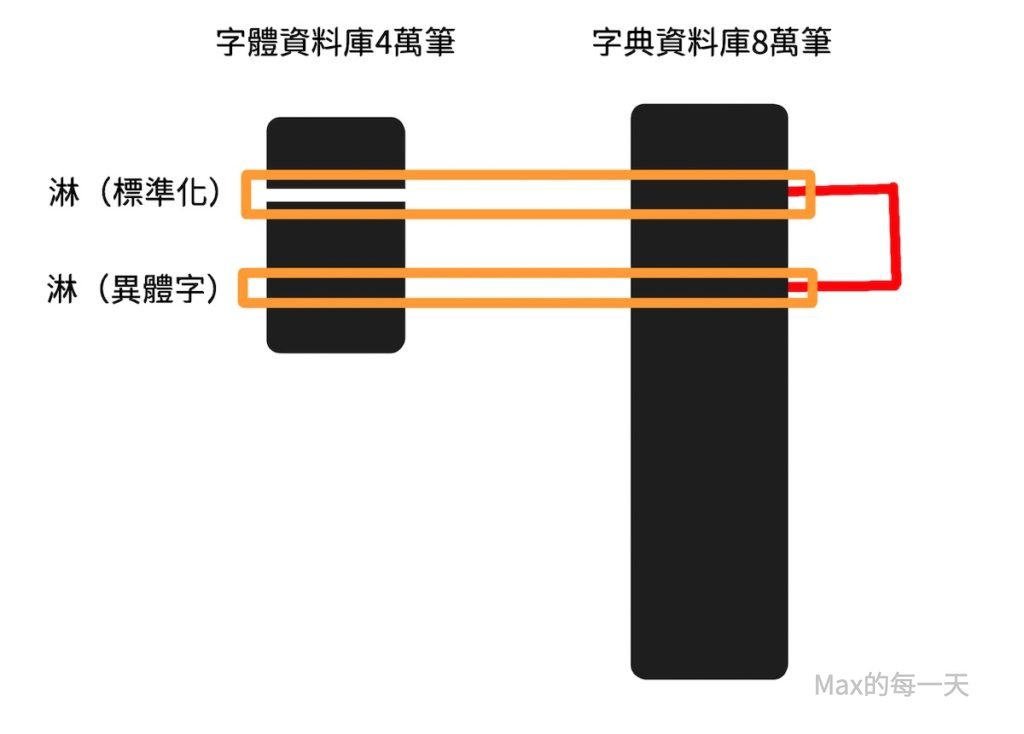
首先,要取得異體字的對應表,需要到別人的網站上去偷資料庫內容,偷完的結果分享如下:
查「部首」、「筆畫」、「異體字」、「同義字」和「文字組件」的字典
https://max-everyday.com/2020/04/chinese-dictionary-radical/
有了對應表後,要把字型檔裡的字都翻一遍出來檢查對應,第一個版本寫的程式跑了15分鐘,居然一個字都沒有比對完成。@_@;只好重新思考解法。
新的解法和Code Review 影片:
https://youtu.be/JX6FnCPtRyw
程式架構:
寫出來的python 副程式:
def compare_dictionary(source_ff, unicode_field, full_dict):
target_unicode_set, target_dict = load_files_to_set_dict(source_ff, unicode_field)
alternate_set = set()
alternate_dict = {}
for char_key in full_dict:
char_dict = full_dict[char_key]
for alternate in char_dict['alternate']:
unicode_int = ord(alternate)
alternate_set.add(unicode_int)
alternate_dict[unicode_int] = ord(char_key)
diff_set_common = target_unicode_set & alternate_set
copy_count = 0
for item in diff_set_common:
if not alternate_dict[item] in target_unicode_set:
target_filename = "uni%s.glyph" % str(hex(alternate_dict[item]))[2:].upper()
source_path = join(source_ff,target_dict[item])
target_path = join(source_ff,target_filename)
shutil.copy(source_path,target_path)
overwrite_config_encoding(target_path, alternate_dict[item], unicode_field)
copy_count += 1
後記:由於資料庫不是很完整,上面的方法後來沒有再使用了,改用直接修改 glyph 檔案,直接比對 unicode code 編碼,符合的話,就增加 “AltUni2: ” 欄位,使用的字典檔:
https://max-everyday.com/2020/04/chinese-dictionary-radical/
Facebook網友回應

