
先說什麼叫「真的免費」。以往 AI 模型的「開源」其實限制很多,大公司通常會規定你不能拿去商業使用,或者不能隨意修改。但這次 4 月 2 日發布的 Gemma 4 採用了 Apache 2.0 授權,白話文就是:你要改就改、要賣就賣、要做成產品直接賺錢都行,完全沒有條件。連 Hugging Face 的執行長都感嘆,這是一個重大的里程碑。
▋ 這次發布的 Gemma 4 到底是什麼?
Google 這次非常有誠意,一口氣推出了四種尺寸,滿足各種設備的需求:
- E2B:只有 23 億參數,小到連入門手機甚至是樹莓派(微型電腦)都能跑。
- E4B:適合平板和筆電,速度比前一代快上 3 倍。
- 26B MoE:這是一種「混合專家」架構,雖然腦容量大,但思考時只會動用一部分零件,所以既快又省電。
- 31B Dense:這是旗艦版本,性能強大到在國際 AI 排行榜直接衝上第三名。
不只如此,它還聽得懂 140 種語言,並且具備「多模態」能力,也就是說它不只能讀文字,連圖片和音訊都能直接理解。
▋ 它到底強在哪?對比前代是跳躍式的進步
如果你覺得 AI 只是會聊天,那 Gemma 4 會讓你改觀。跟上一代相比,它的邏輯能力幾乎是翻倍成長:
- 數學測試:從 20% 的準確率飆升到 89%。
- 程式碼編寫:從 29% 進步到 80%。
- 科學推理:準確率直接翻倍來到 84%。
最驚人的是,那個 31B 的旗艦版本,在實測中打贏了很多體型比它大 20 倍的付費閉源模型。
▋ 你的手機以後就是一台 AI 超級電腦
很多人擔心 AI 很耗電或跑不動,但 Google 這次是認真的。輕量版的 E2B 和 E4B 專為行動裝置設計,比上一代快 4 倍,卻省電 60%。
Google 已經跟高通(Qualcomm)和聯發科(MediaTek)合作優化,預計今年底的新手機就會直接內建這個模型。這意味著:以後你的手機裡會住著一個不需要網路、反應極快,而且完全不會把你的私密資料傳回雲端的 AI 助理。
▋ 這對我們有什麼實際好處?
對一般人來說,最直接的感受就是:
- 出國沒網路也能離線翻譯 140 種語言。
- 語音轉文字在手機本地就能完成,隱私百分之百保留。
- 手機相簿的搜尋會變得極度聰明,它能真正「看懂」你的照片。
對開發者和企業來說,這更是一大福音。醫療、法律或金融這些重視隱私的產業,不再需要擔心資料外洩給第三方 AI 公司,可以直接在自家伺服器跑 Gemma 4,連昂貴的 API 訂閱費都省下來了。
▋ 為什麼 Google 要這麼大方?
這不只是在做慈善,而是一個聰明的生態系策略。當全世界的開發者都習慣用 Google 的開源模型來寫程式、做產品時,Google 就成了 AI 界的標準。雖然模型免費,但當你需要大規模運算時,Google Cloud 雲端平台就是最方便的選擇。
這就像是「送你免費的燈泡,但希望你用我的電」,這正是 Google 建立的 AI 護城河。
如果你的手機不需要連網就能擁有這麼強的 AI,你最希望它幫你處理什麼生活瑣事?
想在自己筆電上跑 AI,但不想學寫程式、不想看黑色指令視窗的科技小白一般用戶,怎麼在電腦裡安裝 gemma 4?
我們將使用目前最簡單、介面最友善的軟體 —— LM Studio。它就像是 AI 界的 App Store,讓你點幾下滑鼠,就能把 Gemma 4 下載到筆電裡,即使沒網路也能聊天。以下是使用教學:
▋ 第一步:準備好你的工具(檢查筆電)
在開始之前,請先確認你的筆電這兩點,跑起來才不會卡頓:
- 記憶體 (RAM): 建議至少 16GB(8GB 勉強能跑最輕量版,但會很慢)。
- 硬碟空間: 至少預留 10GB 以上的空間。
▋ 第二步:下載並安裝 LM Studio
這就像安裝一般電腦軟體一樣簡單:
- 前往官網: 打開瀏覽器,搜尋「LM Studio」,或直接進入
lmstudio.ai。 - 下載軟體: 首頁會大大的寫著「Download LM Studio for Windows」(如果你是用 Mac 或 Linux,它會自動偵測)。
- 執行安裝: 按照螢幕指示完成安裝。安裝完成後,LM Studio 會自動打開。
針對在 Windows 平台筆電上執行模型的需求,建議直接安裝 Windows 原生版本的 LM Studio。原生版本能直接調用 NVIDIA 驅動程式,減少虛擬化層帶來的效能損耗,對於只有 4GB 顯存的入門顯卡來說,能更有效率地分配資源。透過原生介面調整 GPU Offload 參數,也比在 WSL 環境下設定更為直觀穩定,除非有特定的 Linux 開發自動化需求,否則 Windows 版本在安裝便利性與運算效率上都更具優勢。
▋ 第三步:在軟體內搜尋並下載 Gemma 4
LM Studio 最棒的地方,就是可以直接在軟體裡面找模型,不需要去別的網站下載。
- 點擊放大鏡: 在 LM Studio 左側選單中,點擊最上面的 放大鏡圖示 (Search)。
- 輸入關鍵字: 在上方的搜尋框中輸入
Gemma 4,然後按下 Enter。 - 選擇模型: 搜尋結果會出現很多版本。請認明由 Google 官方發布,或者是知名社群成員(如 Bartowski)製作的 GGUF 格式版本。
- 選擇檔案大小 (Quantization): 在右側會看到很多「Download」按鈕,它們代表不同的「壓縮程度」。
- 小白建議: 如果你的筆電是一般性能,請選擇檔案大小約 4GB 到 8GB 之間的版本(通常檔名會有 Q4_K_M 或 Q5_K_M 字樣),這是在精準度和速度之間最好的平衡。
- 點擊下載: 決定好版本後,點擊「Download」。LM Studio 就會開始把 Gemma 4 下載到你的電腦裡。
▋ 第四步:開始跟離線 AI 聊天
下載完成後,你就擁有一個完全屬於你、不用連網的 AI 了!
- 進入聊天介面: 點擊左側選單的 對話氣泡圖示 (AI Chat)。
- 載入模型: 在上方中間的下拉選單中,選擇你剛剛下載的
Gemma 4模型。電腦需要幾秒鐘的時間把模型「讀取」進記憶體。 - 設定系統提示詞(選填): 在右側邊欄,你可以設定 AI 的「個性」。例如,你可以輸入「你是一個專業的繁體中文助手」,它回答的風格就會更符合你的需求。
- 開始打字: 在下方的輸入框中,輸入你想問的問題,例如:「幫我寫一封感謝客戶的繁體中文 Email」,然後按下 Enter。
恭喜你!你已經成功在自己的筆電上跑起了 Google 最新、最強的開源 AI —— Gemma 4。即使現在把 Wi-Fi 關掉,它依然可以回答你的問題。
給喜歡動手實作、對指令介面(CLI)不陌生、追求極致效能與開發彈性的「工程師」或「進階用戶」。下是針對專業用戶的 Ollama 安裝與 Gemma 4 部署教學:
我們將使用目前在 Linux/macOS(Windows 也即將推出穩定版)社群中極受歡迎的開源專案 —— Ollama。它讓你在本地端部署大語言模型(LLM)變得像使用 Docker 一樣簡單、快速且標準化。
▋ 第一步:環境準備與硬體建議
在開始之前,請確保你的開發環境滿足以下條件,以獲得最佳效能:
- 作業系統 (OS):
- macOS: 建議使用 Apple Silicon (M1/M2/M3) 晶片,並更新至較新版本。
- Linux: 建議使用 Ubuntu 22.04+ 或其他主流發行版,並確認 GPU 驅動已正確安裝。
- Windows : 目前已有預覽版,但穩定性與效能可能稍遜,建議優先使用 WSL2 或原生 Linux。
- 記憶體 (RAM): 建議 32GB 或以上。若需載入旗艦版 31B 模型,建議至少 64GB。
- GPU (非必須,但強烈建議):
- NVIDIA GPU: 需支援 CUDA,且顯示記憶體 (VRAM) 建議 16GB 以上(對應 Q4 量化模型)。
- Apple Silicon: 由於採用統一記憶體架構,硬體會自動分配系統記憶體作為 VRAM。
- 硬碟空間: 預留至少 50GB 供模型檔案使用。
▋ 第二步:安裝 Ollama
Ollama 的安裝過程非常精簡,只需一行指令(Linux/macOS):
在終端機 (Terminal) 執行安裝指令:
curl -fsSL https://ollama.com/install.sh | sh 這行指令會自動偵測你的作業系統、下載對應的二進位檔案、將其移動到 /usr/local/bin(或其他合適路徑),並將 ollama 註冊為系統服務(Systemd service,Linux環境下)。
驗證安裝: 安裝完成後,輸入以下指令確認 Ollama 伺服器已正常運作:
ollama --version如果成功顯示版本號,代表 Ollama 已經就緒。
▋ 第三步:一鍵部署 Gemma 4
Ollama 的核心優勢在於其「模型倉庫」機制。你不需要手動下載 GGUF 檔案,只需指定模型名稱,Ollama 就會自動完成下載、量化(如果需要)與載入。
在終端機執行 run 指令:
ollama run gemma4注意: 如果你想要指定特定的尺寸(例如 31B),可以使用 tag:
ollama run gemma4:31b背後發生的事: Ollama 會先檢查本地端是否有 gemma4 模型。如果沒有,它會自動前往 Ollama Registry 下載對應的檔案。下載完成後,它會自動將模型載入記憶體(或 GPU),並直接在終端機中開啟一個互動式的聊天介面。
查詢已下載模型的方法
要在本機查詢 Ollama 已經下載的所有模型列表,最直接的方式是開啟終端機(命令提示字元或 PowerShell),並輸入指令:
ollama list這個指令會條列出目前儲存在你硬碟中的所有模型名稱、版本標籤(ID)、檔案大小以及最後修改時間。
檢查模型量化內容
ollama show [模型名稱]
執行結果:
Model
architecture gemma4
parameters 5.1B
context length 131072
embedding length 1536
quantization Q4_K_M
requires 0.20.0
Capabilities
completion
vision
audio
tools
thinking確認目前的版本是 Gemma 4 (5.1B) 的 Q4_K_M,且在 YAO-NB 筆電上反應仍然太慢,你可以嘗試的調整方向:
使用極度量化版本 (IQ 或 Q2/Q3)
如果你堅持要用 5.1B 模型的智慧,但又嫌 Q4_K_M 太慢,可以犧牲一點點準確度來換取速度:
- Q3_K_S 或 Q2_K:這類版本會進一步壓縮權重。雖然邏輯能力會下降,但因為檔案更小,對記憶體頻寬的需求降低,速度會變快。
- IQ4_XS:如果你能找到支援權重量化的版本,這類版本在低位元下效能優化得很好。
▋ 第四步:整合應用與進階開發
作為專業用戶,你可能不只是想在終端機跟 AI 聊天,而是想將其整合進你的工作流或 App 中。
1. 使用 REST API 進行整合
Ollama 預設會在本地端開啟 port 11434 提供 REST API 服務。
產生回應 (Generation):
Windows CMD mode
curl http://localhost:11434/api/generate -d "{\"model\":\"gemma4\", \"prompt\":\"為什麼開源對 AI 發展很重要?\", \"stream\":false}"Windows PowerShell
$body = @{
model = "gemma4"
prompt = "為什麼開源對 AI 發展很重要?"
stream = $false
}
Invoke-RestMethod -Uri http://localhost:11434/api/generate -Method Post -Body ($body | ConvertTo-Json)macOS / Linux
curl http://localhost:11434/api/generate -d '{"model":"gemma4", "prompt":"為什麼開源對 AI 發展很重要?", "stream":false}'產生對話 (Chat):
curl http://localhost:11434/api/chat -d '{
"model": "gemma4",
"messages": [
{ "role": "user", "content": "你好,介紹一下 Gemma 4 的 Apache 2.0 授權。" }
],
"stream": false
}'2. 整合知名開源 UI 專案
如果你喜歡 LM Studio 那樣的網頁圖形介面,但想使用 Ollama 作為後端,可以配合以下開源專案:
Open WebUI (前身為 Ollama WebUI): 功能極其強大,介面與 ChatGPT 非常相似,支援多模型管理、RAG、使用者權限等。通常建議使用 Docker 部署。
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main部署後打開瀏覽器訪問 http://localhost:3000 即可。
恭喜你!你已經成功使用 Ollama 在本地端部署了 Google 最新、最強的開源 AI —— Gemma 4。無論是直接在終端機互動、通過 REST API 整合進你的專案,或是配合強大的 Web UI,Ollama 都為專業用戶提供了無與倫比的靈活性與效能。
要在 Gemini CLI(如 Google 推出的開源 gemini-cli 或類似工具)中串接本地的 Gemma 4,最常見的做法是透過環境變數重新導向 API 的請求路徑。由於 Ollama 提供與 OpenAI 相容的 API 接口,你可以將 Gemini CLI 指向本地的 Ollama 伺服器。
環境變數設定與啟動
你需要設定 GOOGLE_GEMINI_BASE_URL(或工具指定的 Base URL 變數)指向 Ollama 的 API 終點,並提供一個虛擬的 API Key。在 Windows 的 CMD 中,請執行以下指令:
DOS
set GOOGLE_GEMINI_BASE_URL=http://localhost:11434/v1
set GEMINI_API_KEY=any_dummy_key
gemini --model ollama/gemma4:2b
如果你使用的是 PowerShell,指令如下:
PowerShell
$env:GOOGLE_GEMINI_BASE_URL="http://localhost:11434/v1"
$env:GEMINI_API_KEY="any_dummy_key"
gemini --model ollama/gemma4:2b
模型別名與相容性注意
Gemini CLI 內部有時會區分主要模型與分類模型(如 flash 或 lite 系列)。如果你發現啟動時出現模型名稱不符的錯誤,可能需要在設定檔中針對本地模型設定別名。此外,Gemma 4 在 Ollama 的模板中必須支援 Tool Calling,Gemini CLI 才能正常運作其代理人(Agent)功能。如果遇到 does not support tools 的錯誤,建議改用支援該功能的模型標籤,或單純將其作為純對話模型使用。
確認 Ollama 服務狀態
在串接之前,請務必確認 Ollama 正在後台運行(工作列有圖示,或執行過 ollama serve)。你可以先用 ollama list 確認 gemma4 是否已存在。如果 CLI 回傳連線失敗,請檢查 http://localhost:11434 是否能正常存取。透過這種方式,Gemini CLI 就會把原本要發送給 Google 雲端的請求,轉向你本地顯卡上的 Gemma 4 進行運算。
當 Ollama 安裝在 Windows 主機,而你的 Gemini CLI 或 curl 指令是在 WSL 內部執行時,WSL 看到的 127.0.0.1 是指 WSL 虛擬機自己,而不是外面的 Windows 主機。因此,你需要透過特定的 IP 或主機名來跨越這層虛擬網路邊界。
解決連線問題的關鍵位址
在 WSL 中,你可以使用 localhost(前提是 WSL 版本較新且開啟了自動映射)或者使用專屬的特殊主機名 host.docker.internal(如果你有安裝 Docker Desktop)來代表 Windows 主機。最通用的做法是直接使用 $(hostname).local 或透過 cat /etc/resolv.conf 找到的 nameserver 位址。
請嘗試將指令修改為以下格式:
Bash
curl http://$(hostname).local:11434/api/generate -d '{"model":"gemma4", "prompt":"為什麼開源對 AI 發展很重要?", "stream":false}'
環境變數的串接設定
如果你要在 WSL 裡面的 Gemini CLI 串接 Windows 的 Ollama,請在 WSL 的 .zshrc 或 .bashrc 設定環境變數。同樣地,位址不能寫 127.0.0.1。
設定範例:
Bash
export GOOGLE_GEMINI_BASE_URL="http://$(hostname).local:11434/v1"
export GEMINI_API_KEY="any_dummy_key"
段落標題:Windows 防火牆與 Ollama 監聽設定
即便位址寫對了,如果 Ollama 只監聽在 Windows 內部的 127.0.0.1,它會拒絕來自 WSL 的連線(對 Windows 來說這算外部請求)。
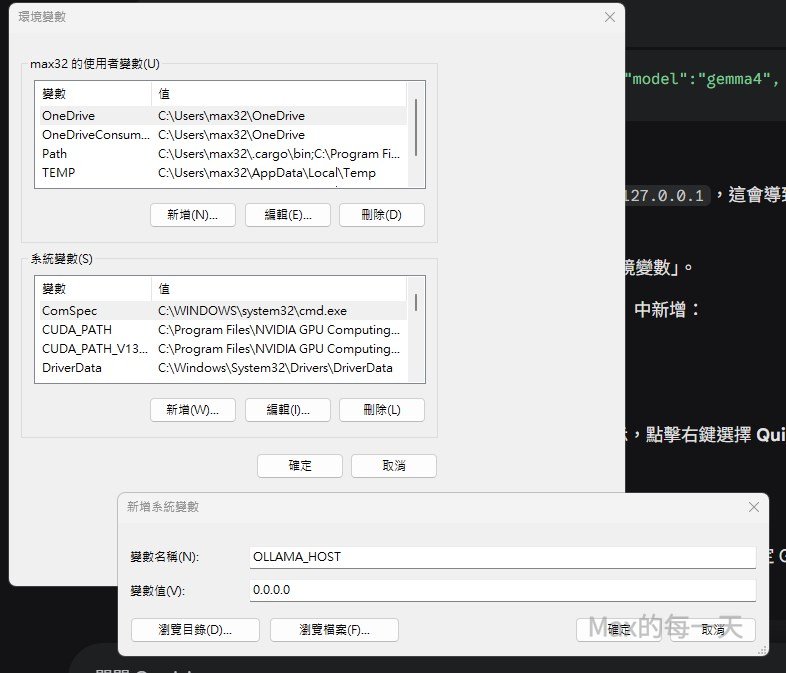
請在 Windows 的環境變數中新增一個系統變數:
變數名稱:OLLAMA_HOST
變數值:0.0.0.0
設定完成後,必須「完全退出」並重啟 Windows 上的 Ollama 程式。這樣 Ollama 才會接受來自所有網路介面(包含 WSL 虛擬網卡)的請求。同時,請確認 Windows 防火牆沒有阻擋 11434 埠號的入站連線。
根據你的 resolv.conf 內容,你的 WSL 正在使用自動生成的 DNS 設定。要從 WSL 存取 Windows 宿主機上的 Ollama 服務,請依照以下步驟操作,這能解決 127.0.0.1 無法連線的問題。
直接使用 Windows 宿主機 IP
在 WSL 2 中,Windows 宿主機的 IP 通常就是 resolv.conf 裡面的 nameserver 位址。你可以直接嘗試將 API 指向該位址:
Bash
curl http://10.255.255.254:11434/api/generate -d '{"model":"gemma4", "prompt":"為什麼開源對 AI 發展很重要?", "stream":false}'
設定 Ollama 允許外部連線
這是最關鍵的一步。預設情況下,Windows 版 Ollama 只監聽 127.0.0.1,這會導致它拒絕任何來自 WSL 的連線。
- 在 Windows 搜尋列輸入「環境變數」,選擇「編輯系統環境變數」。
- 點擊「環境變數」按鈕,在「使用者變數」或「系統變數」中新增:
- 變數名稱:OLLAMA_HOST
- 變數值:0.0.0.0
- 設定完成後,請務必在系統工作列右下角找到 Ollama 圖示,點擊右鍵選擇 Quit Ollama,然後重新啟動 Ollama。
在 WSL 中串接 Gemini CLI
一旦確認上述 curl 指令可以成功拿到回應,你就可以在 WSL 的 .zshrc 中設定 Gemini CLI 需要的環境變數。
Bash
# 加入到 ~/.zshrc
export GOOGLE_GEMINI_BASE_URL="http://10.255.255.254:11434/v1"
export GEMINI_API_KEY="local-only"
存檔後執行 source ~/.zshrc。之後在使用 Gemini CLI 時,它就會透過 10.255.255.254 這個通道,跨過虛擬網路去讀取你 Windows 上的 GTX 1650 所跑的模型了。
檢查 Windows 防火牆
如果還是連不上,請檢查 Windows Defender 防火牆。確保它允許 Ollama.exe 接收來自公用或專用網路的入站連線,或者手動新增一條規則,允許 TCP 11434 埠號通過。這是因為對 Windows 來說,WSL 的連線被視為來自另一個網路介面的外部請求。
從你的設定來看,OLLAMA_HOST=0.0.0.0 已經正確生效,且 ping 也能通,代表網路層是對的。連線失敗通常是因為 Windows 版 Ollama 雖然設定了環境變數,但服務本身沒有完全「重啟」以套用新設定,或是被防火牆擋住。
強制重啟 Ollama 服務
Windows 環境變數修改後,必須完全關閉進程才會生效。請不要只關閉視窗,請到系統右下角的小圖示找到 Ollama,點擊右鍵選擇 Quit Ollama。接著,開啟一個新的 CMD 視窗,輸入 set O 確認 OLLAMA_HOST=0.0.0.0 還在,然後在該視窗輸入 ollama serve 直接啟動。這能確保它真的監聽在所有介面上。
段落標題:Windows 防火牆入站規則
即使設定了 0.0.0.0,Windows 防火牆預設可能會封鎖來自非本機(對 Windows 來說 WSL 的 IP 算外部)的 11434 埠號請求。請在 Windows 搜尋「進階安全資訊防火牆」,進入後在 入站規則 點擊「新增規則」。選擇「連接埠」,輸入 TCP 11434,並設定為「允許連線」。確保該規則涵蓋「公用」與「專用」設定檔。
確認監聽狀態
在 Windows 的 CMD 視窗中輸入以下指令,確認 Ollama 是否真的有在 0.0.0.0:11434 進行監聽:
netstat -ano | findstr 11434
如果你看到顯示的是 0.0.0.0:11434 或 *:11434,代表監聽設定成功;如果還是看到 127.0.0.1:11434,代表你的環境變數設定並沒有被 Ollama 載入,請重新檢查系統變數設定並重啟電腦。
WSL 端的最終測試
當上述兩項都完成後,回到 WSL 再次執行 curl 指令。如果還是失敗,請嘗試將 10.255.255.254 更換為 $(hostname).local。這是因為 WSL 2 的網路架構有時會對硬編碼的 IP 有不同的路徑處理方式,使用主機名稱通常能透過 mDNS 自動解析到正確的介面。
netstat:
C:\Users\max32>netstat -ano | findstr 11434
TCP 0.0.0.0:11434 0.0.0.0:0 LISTENING 832
TCP 127.0.0.1:11434 127.0.0.1:11434 TIME_WAIT 0
TCP 127.0.0.1:11434 127.0.0.1:11552 ESTABLISHED 832
TCP 127.0.0.1:11552 127.0.0.1:11434 ESTABLISHED 11660
TCP [::]:11434 [::]:0 LISTENING 832
你的 netstat 結果顯示 0.0.0.0:11434 正在 LISTENING,這代表 Ollama 已經正確設定並允許來自所有介面的連線。既然連線設定沒問題但 curl 仍失敗,問題極大機率出在 Windows 防火牆或是 WSL 2 的網路路徑。
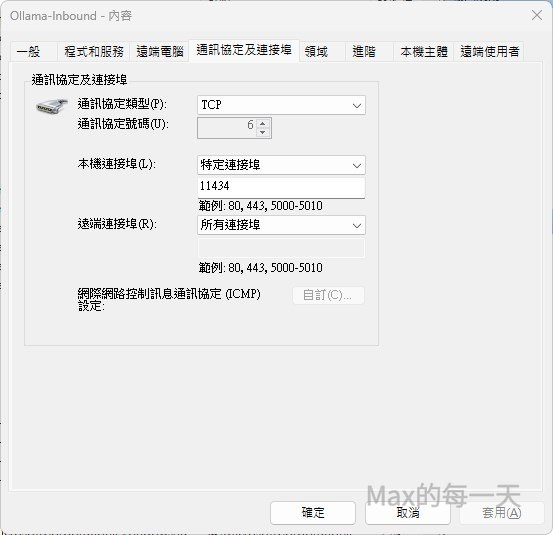
手動開啟 Windows 防火牆規則
即便 Ollama 開啟了監聽,Windows 防火牆預設會阻擋來自虛擬網卡(WSL)的入站流量。請依以下步驟排除:
- 按下
Win + R,輸入control firewall.cpl並按確認。 - 點擊左側的「進階設定」。
- 在「輸入規則」點擊右側的「新增規則」。
- 選擇「連接埠」 > 「TCP」 > 特定本地連接埠輸入
11434。 - 選擇「允許連線」,並確保「網域、專用、公用」三個選項都勾選。
- 取名為
Ollama-Inbound後儲存。
更換 WSL 存取位址
WSL 2 的網路有時會對硬編碼的 IP(如 10.255.255.254)反應遲鈍。請在 WSL 終端機嘗試使用 Windows 的主機名稱,這通常能繞過奇怪的路由問題。在 WSL 中輸入:
Bash
curl http://$(hostname).local:11434/api/generate -d '{"model":"gemma4", "prompt":"為什麼開源對 AI 發展很重要?", "stream":false}'
確認 Windows 宿主機真實 IP
如果 $(hostname).local 無效,請在 Windows 的 CMD 輸入 ipconfig,找到 Ethernet adapter vEthernet (WSL) 這一項目的 IPv4 Address。這才是 Windows 給予 WSL 通訊的真實入口 IP。假設該 IP 是 172.x.x.x,請在 WSL 的 curl 指令中使用這個位址。
關閉代理伺服器干擾
如果你在 WSL 中有設定 http_proxy 或 https_proxy 環境變數(這在開發環境很常見),curl 可能會嘗試透過代理伺服器去連線 10.255.255.254,導致連線失敗。請在執行前輸入 unset http_proxy https_proxy 清除暫時變數後再試一次。或是將該 IP 加入 no_proxy 清單中。
ipconfig:
乙太網路卡 vEthernet (WSL (Hyper-V firewall)):
連線特定 DNS 尾碼 . . . . . . . . :
連結-本機 IPv6 位址 . . . . . . . : fe80::5e65:9c0c:d4e4:a01b%45
IPv4 位址 . . . . . . . . . . . . : 172.30.16.1
子網路遮罩 . . . . . . . . . . . .: 255.255.240.0
預設閘道 . . . . . . . . . . . . .:
根據你的 ipconfig 結果,Windows 在 WSL 虛擬網卡上的 IP 位址是 172.30.16.1。這就是你在 WSL 裡面應該連線的對象。你之前嘗試的 10.255.255.254 是 DNS 伺服器位址,不一定是宿主機的通訊 IP。
更換為正確的宿主機 IP
請在 WSL 中使用 172.30.16.1 重新測試連線。這個位址是 Windows 專門配發給 WSL 通訊用的閘道位址:
Bash
curl http://172.30.16.1:11434/api/generate -d '{"model":"gemma4", "prompt":"為什麼開源對 AI 發展很重要?", "stream":false}'
處理 Hyper-V 防火牆攔截
注意到你的網卡名稱顯示為 vEthernet (WSL (Hyper-V firewall))。這代表 Windows 的 Hyper-V 防火牆功能正在監控這個介面。如果上述 curl 指令仍然失敗(出現 Connection refused 或 Timeout),請務必檢查 Windows 防火牆設定。你可以在 Windows 的 PowerShell (系統管理員) 執行以下指令,快速允許 WSL 存取宿主機:
PowerShell
New-NetFirewallRule -DisplayName "Allow WSL Ollama" -Direction Inbound -Action Allow -Protocol TCP -LocalPort 11434 -RemoteAddress 172.30.16.0/20
教學文章:
Using Gemini CLI with a Local LLM
https://dev.to/polar3130/using-gemini-cli-with-a-local-llm-5f5l
這取決於你希望如何管理開發環境。考量到你目前的配置(Ollama 在 Windows,Gemini CLI 在 WSL),將 LiteLLM 安裝在 WSL 會是比較順暢的選擇。
為什麼建議安裝在 WSL
因為你的 Gemini CLI 已經在 WSL 的虛擬環境(.venv)中執行,將 LiteLLM 同樣安裝在 WSL 可以讓它們直接透過 localhost 通訊,減少跨網路層的複雜度。LiteLLM 將扮演中繼站的角色:Gemini CLI 連往 WSL 內部的 LiteLLM,而 LiteLLM 再連往 Windows 的 Ollama(172.30.16.1)。
安裝與啟動步驟
在 WSL 的虛擬環境中,你可以透過 pip 快速安裝並啟動代理服務。請執行以下指令:
Bash
pip install 'litellm[proxy]'
建議建立一個 config.yaml 檔案,例如放在 ~/litellm/config.yaml,將 Gemini CLI 預設尋找的模型名稱轉向本地。
建立 config.yaml:
model_list:
- model_name: "gemma4:e2b"
litellm_params:
model: "ollama_chat/gemma4:e2b"
api_base: "http://172.30.16.1:11434"
然後以此設定檔啟動:
litellm --config config.yaml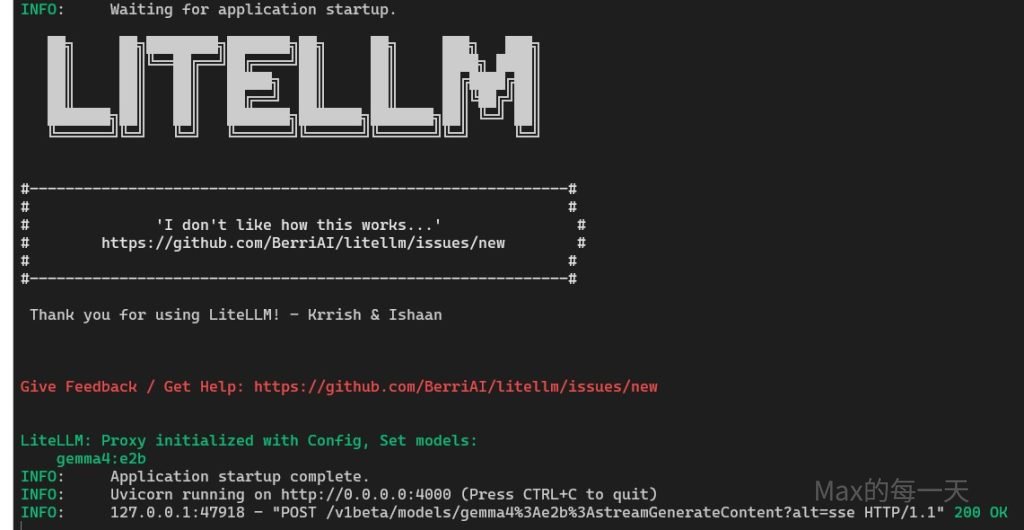
上圖看的到, 已經有拿到 gemini cli 的訊息, 並回傳 http 200 狀態碼, 成功.
Gemini CLI 指令
當 LiteLLM 啟動後,它預設會監聽在 WSL 的 http://0.0.0.0:4000。此時,你只需要修改 Gemini CLI 的環境變數,將其指向這個本地代理即可:
export GOOGLE_GEMINI_BASE_URL="http://127.0.0.1:4000"
export GEMINI_API_KEY="anything"
gemini --model gemma4:e2b
這個錯誤訊息 429 RateLimitError 非常明確,代表你使用的 OpenRouter 免費模型 gemma-4-26b-a4b-it:free 目前在後端(Google AI Studio)已經達到了流量限制。由於這是免費共享配額,當熱門時段使用者過多時,就會出現這種「暫時性限流」。
解決 429 限流的策略
你可以透過 LiteLLM 的「故障轉移」(Fallback)功能來解決這個問題。當一個帳號或模型掛掉時,自動切換到另一個備用方案。
請修改你的 config.yaml,加入模型組(Router)的概念:
YAML
model_list:
# 帳號 A 的免費模型
- model_name: "gemma-cluster"
litellm_params:
model: "openrouter/google/gemma-4-26b-a4b-it:free"
api_key: "帳號1_的_KEY"
api_base: "https://openrouter.ai/api/v1"
# 帳號 B 的免費模型(備援)
- model_name: "gemma-cluster"
litellm_params:
model: "openrouter/google/gemma-4-26b-a4b-it:free"
api_key: "帳號2_的_KEY"
api_base: "https://openrouter.ai/api/v1"
router_settings:
routing_strategy: "usage-based-routing-v2" # 自動選擇負載較輕的
enable_fallbacks: true
多樣化備援模型
不要只依賴同一個免費模型,因為當該模型後端(如 Google AI Studio)限流時,所有帳號可能都會同時受影響。建議在 fallback 清單中加入不同供應商的免費模型:
YAML
- model_name: "gemma-cluster"
litellm_params:
model: "openrouter/meta-llama/llama-3.1-8b-instruct:free" # 換成 Llama 備援
api_key: "你的_KEY"
增加 LiteLLM 的重試機制
目前的錯誤顯示 LiteLLM 已經重試了 2 次。你可以在啟動指令或設定中增加重試次數,有時候多等幾秒鐘配額就會釋放出來:
Bash
# 啟動時增加重試次數
litellm --config config.yaml --num_retries 5
Gemini CLI 的對應調整
因為你現在把多個模型封裝成了 gemma-cluster,所以你在執行 Gemini CLI 時,模型名稱要改成對應這個群組:
Bash
gemini --model gemma-cluster
這樣一來,當 OpenRouter 回傳 429 錯誤時,LiteLLM 會自動幫你換下一個 API Key 或是換到下一個模型,你的終端機對話就不會被中斷了。
Google #Gemma4 #人工智慧 #開源模型 #Gemini #科技趨勢 #AI手機


