看完這篇文章(或影片)你會學到:
- 增加電腦字形一點點知識
- 如何轉換ttf 為 ufo / ufo 轉為 ttf
- 如何比對2個字型檔的缺字情況
- 顯示文字對應到的unicode字碼
MaxCodeReview:
https://youtu.be/HSxRJ7_MyJQ
Max發現有一個好心人(游清松),花了很多時間去寫手寫字,並把字變成字型檔開放免費下載,我在過年期間隨手幫他弄了一個網頁:
https://jasonfonts.max-everyday.com/
原作者說,暫時他還沒有打算架網頁,如果未來有需要再找來請教我。
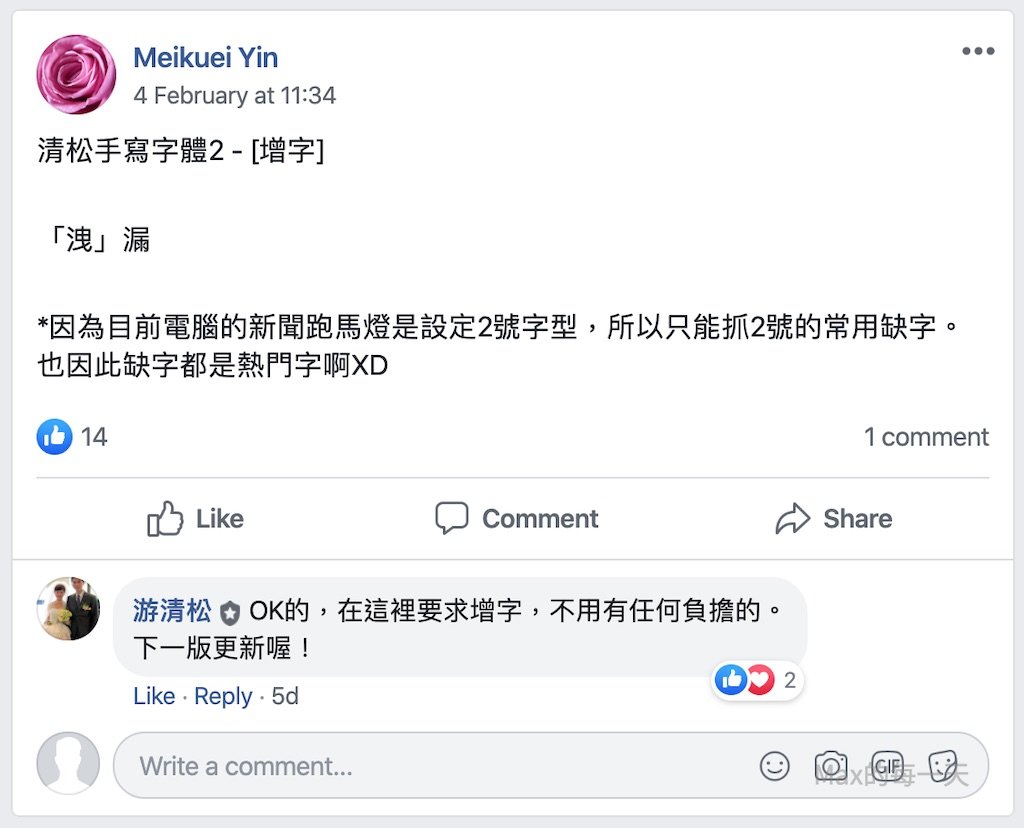
我發現有人在社團裡提出增字的要求:
Max 使用的Python程式碼轉換 ttf 為 ufo:
import extractor
import defcon
ufo = defcon.Font()
extractor.extractUFO("JasonFonts1.ttf", ufo)
ufo.save("JasonFonts1.ufo", removeUnreferencedImages=True)
ufo = defcon.Font()
extractor.extractUFO("JasonFonts2.ttf", ufo)
ufo.save("JasonFonts2.ufo", removeUnreferencedImages=True)
ufo = defcon.Font()
Max 使用的Python程式碼比對缺字,並輸出比較結果到文字檔:
def output_to_file(myfile, myfont_set):
for item in myfont_set:
output_string = "%s(%s)" % (chr(item),str(hex(item))[2:])
myfile.write(output_string)
import defcon
ufo_font1 = defcon.Font(path="JasonFonts1.ufo")
set_font1 = set()
for glyph in ufo_font1:
set_font1.add(glyph.unicode)
ufo_font2 = defcon.Font(path="JasonFonts2.ufo")
set_font2 = set()
for glyph in ufo_font2:
set_font2.add(glyph.unicode)
print("start to compare…")
print("1 have 2 without")
filename_output = "diff_1_sub_2.txt"
outfile = open(filename_output, 'w')
diff_1_sub_2 = set_font1 - set_font2
sorted_set=sorted(diff_1_sub_2)
output_to_file(outfile,sorted_set)
outfile.close()
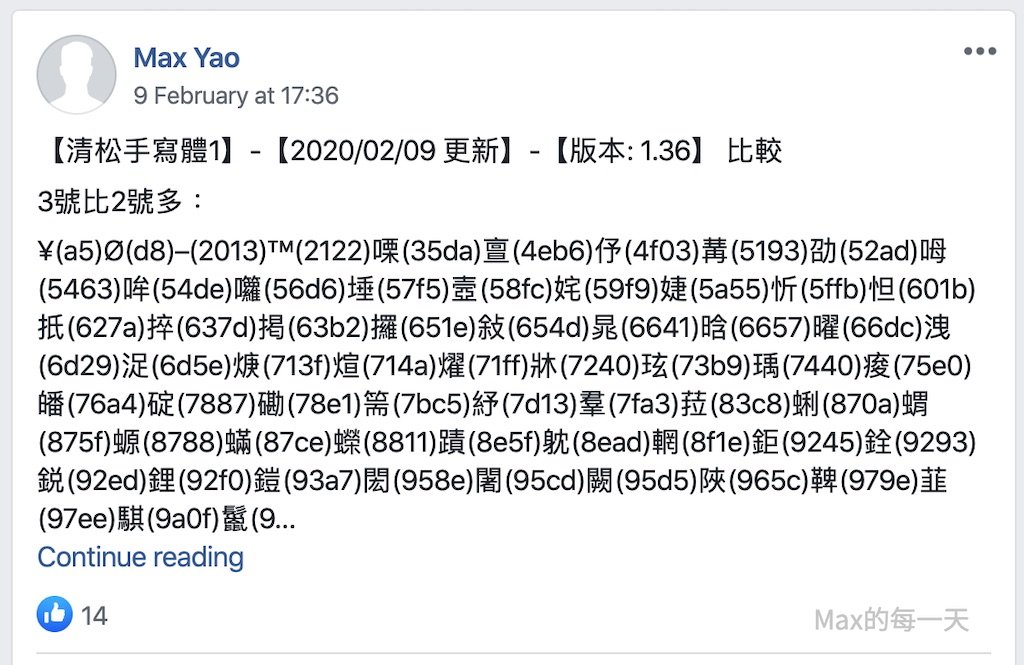
最後貼上比較的結果:
轉成 ufo 格式有點麻煩,Max 後來是直接使用 FontForge 的資料夾格式去進行缺字的比對,使用的程式碼如下:
from os import listdir, remove
from os.path import join, exists
import shutil
def output_to_file(myfile, myfont_set):
for item in myfont_set:
try:
output_string = "%s(%s)" % (chr(item),str(hex(item))[2:])
except Exception as exc:
print("error item:%d" %(item))
print("error item(hex):%s" %(str(hex(item))))
raise
myfile.write(output_string)
def load_unicode_from_file(filename_input):
mycode = 0
myfile = open(filename_input, 'r')
left_part = 'Encoding: '
left_part_length = len(left_part)
for x_line in myfile:
#print(x_line)
if left_part == x_line[:left_part_length]:
right_part = x_line[left_part_length:]
if ' ' in right_part:
mychar_array = right_part.split(' ')
if len(mychar_array) > 0:
mycode = int(mychar_array[0])
#print("bingo")
break
myfile.close()
return mycode
def load_files_to_set_dict(ff_folder):
my_set = set()
my_dict = {}
files = listdir(ff_folder)
for f in files:
if '.glyph' in f:
unicode_info = load_unicode_from_file(join(ff_folder,f))
if unicode_info > 0 and unicode_info < 0x110000:
#print('code:', unicode_info)
my_set.add(unicode_info)
my_dict[unicode_info] = f
#break
return my_set, my_dict
source_ff = 'JasonHandwriting1-Regular.sfdir'
target_ff = 'JasonHandwriting2-Regular.sfdir'
source_unicode_set, source_dict = load_files_to_set_dict(source_ff)
target_unicode_set, target_dict = load_files_to_set_dict(target_ff)
print("length source:", len(source_unicode_set))
print("length target:", len(target_unicode_set))
diff_set_more = target_unicode_set - source_unicode_set
diff_set_lost = source_unicode_set - target_unicode_set
diff_set_common = source_unicode_set & target_unicode_set
print("length more:", len(diff_set_more))
print("length lost:", len(diff_set_lost))
print("length common:", len(diff_set_common))
print("output compare result to file...")
filename_output = "diff_base_sub_%s.txt" % (target_ff)
outfile = open(filename_output, 'w')
sorted_set=sorted(diff_set_more)
output_to_file(outfile,sorted_set)
outfile.close()
如果是想合併 2個字型檔,也可以服用下面的 code:
conflic_count = 0
copy_count = 0
for item in diff_set_more:
target_path = join(target_ff,target_dict[item])
source_path = join(source_ff,target_dict[item])
if exists(source_path):
print("conflic:", source_path)
conflic_count += 1
else:
shutil.copy(target_path, source_path)
copy_count += 1
如果是想刪除2個字型檔裡,共用的部分,只留下差異的文字,請服用下面的code:
remove_count = 0
for item in diff_set_common:
target_path = join(target_ff,target_dict[item])
remove(target_path)
remove_count += 1
與其使用 ufo 格式,不用直接使用 FontForge 的檔案,方便很多,也更容易產生成新的字型檔案,在編輯字型上也很方便。
要刪字或增字,只要直接去存取FontForge資料夾下的 .glyph 的檔案就完成了。
上面的Python程式碼,可以在Windows/macOS/Linux平台上使用。
如果是想比對特定文章裡的字串,在字型檔裡有沒有缺字,可以使用下面文章裡的程式:
常見的「台灣方言字」整理
https://max-everyday.com/2020/03/taiwanese-common-word-700/
附註(非商用):
- 「教育部 4808 個常用字」係指民國 71 年 9 月 1 日教育部公告的「常用國字標準字體表」所收錄之常用字。
- 教育部標準楷書字形檔(Version 4.00),目前收錄國字數為 13,076 字。
https://language.moe.gov.tw/001/Upload/Files/site_content/M0001/edukai-4.0.zip - 教育部隸書字形檔(Version 3.00),目前收錄國字數為4,808字。
https://language.moe.gov.tw/001/Upload/Files/site_content/M0001/MoeLI-3.0.zip - 教育部標準宋體字形檔 :
https://language.moe.gov.tw/001/Upload/Files/site_content/M0001/eduSong_Unicode.zip
附註(可商用):
- マメロン Regular
https://moji-waku.com/mamelon/ - 花園明朝:
http://osdn.jp/projects/hanazono-font/releases/
日本花園明朝體(HanaMin)是一款非常漂亮的藝術字體,包含近十萬字,所以不必擔心缺字,有分割成HanaMinA、HanaMinB兩個字體檔,安裝A就好了,在macOS 裡 HanaMinB 會有問題,會跳回去PingFang 並變粗體字。 - 王漢宗自由字型:(193MB)
https://drive.google.com/file/d/1eM7bpKCdcZc1i7QGIhXiUquS2TFCbXUf/view - M+ FONTS PROJECT
http://mplus-fonts.osdn.jp/about.html - Fandol字体(4款)仿宋 黑体 楷体 宋体
https://ctan.org/pkg/fandol
Fandol系列字体来自一家已经破产的字体公司,现在已经开源了。 - 瀨戶字體
https://zh-tw.osdn.net/projects/setofont/
瀨戶字體是一個由日本人開發的線上免費字體,支援繁體中文、簡體中文、日文、英文和其他特殊符號,總共支援3萬多個漢字。 - 楊任東竹石體
http://www.fonts.net.cn/author-6289251609-1.html
上面的這個版本,字型檔案好像有點問題,有些字會出錯。改下載這個版本即可解決:
https://m.fontke.com/font/28225026/
出錯的原因是在版本號,第一個連結是 1.2 版,後面的是 1.5版,1.5版才有支援繁體字,可是 1.5 版的字重被調重了,相當於1.2版的 Medium。
“杨任东字体”微信公众号
https://www.weibo.com/p/1005053026020863/info?mod=pedit_more
好年輕的人哦,生日:1993年12月30日。 - TanukiMagic 麥克筆手繪 POP 日文字型:
http://tanukifont.com/tanuki-permanent-marker/ - 日系851原子筆手寫風格字型,可商用免費下載
https://pm85122.onamae.jp/851fontpage.html
相關文章:
Python 字型相關工具
https://stackoverflow.max-everyday.com/2020/02/python-font/
FontTools 安裝與使用簡明指南
https://stackoverflow.max-everyday.com/2020/02/fonttools/
FontForge
https://github.com/fontforge/fontforge/releases
Awesome Typography
https://github.com/Jolg42/awesome-typography
免費中文字體 NotoSans 思源黑體
https://max-everyday.com/2018/03/noto-font/
free and carefree: 可以免費商用的中文或漢字字型
https://tips.justfont.com/post/113397509827/freeandcarefreefonts
免費商用字體整理
https://max-everyday.com/2020/02/free-commercial-fonts/
FontForge 調整字型在 Windows 的安裝顯示名稱
https://stackoverflow.max-everyday.com/2020/02/fontforge-chinese/
內海字體 (NaikaiFont)
https://max-everyday.com/2020/03/naikaifont/
幫字型檔補缺字
https://max-everyday.com/2020/02/how-to-add-new-glyph-to-font/