當 AI 氾濫、學術語意泡沫化,一個研究者要如何證明:「這篇論文,是我自己想出來的?」
2026-06-10(二) 去聽一堂演講,快下課時我被點名來發言:
超尷尬的, 他還問我是教授嗎? 我回, 我是旁聽的路人甲, 他回: 沒關係, 那就你先來提問.
我回:有辦法加入 loop engineering, 跟現在 AI 都回答的比人類更清楚更明白, 還有需要人類進行口試回答嗎?
他回要 loop 加一句提示詞 AI 就可以做到, AI 都回答的比人類更清楚更明白, 他回答是偏向自己向自己負責.
大致上是回答, 這個世界不會有其他人在意你寫了什麼論文, 你的論文對世界有什麼貢獻, 做為一個學者或研究員, 你能要求就是自己比別人更明白你的的產品在做什麼及為什麼選這一個實作方法, 不同方法有什麼差異與不同, 在沒有 AI 的時代, 論文或PPT 上簽上你的名字, 代表你在當下與該論文可以畫上等號, 但有了 AI 之後, 現在的簡報 AI 做的比人類強, 論文也寫的比人類好, 用 AI 產生出來的論文寫的人可能只是下了一段 prompt 論文就生出來了, 你與別人的差異就只有在有沒有使用 AI. 在這個情況下, 我們應該把注意力或焦點放在那裡? 怎麼透過 AI 去放大我們的能力.
台下還有人在看 netflix 和忙著剪輯自己的課外影片中, 感覺大約 1/3 學生沒有心思在聽, 邊忙著自己其他的事情, 猜測這些研究生應該只求可以順利畢業, 有 AI 世代, 研究所應該可以輕鬆畢業, 那個看影片的感覺心臟應該很強大, 他的指導教授應該也很頭大, 這種學生要怎麼指導他們.
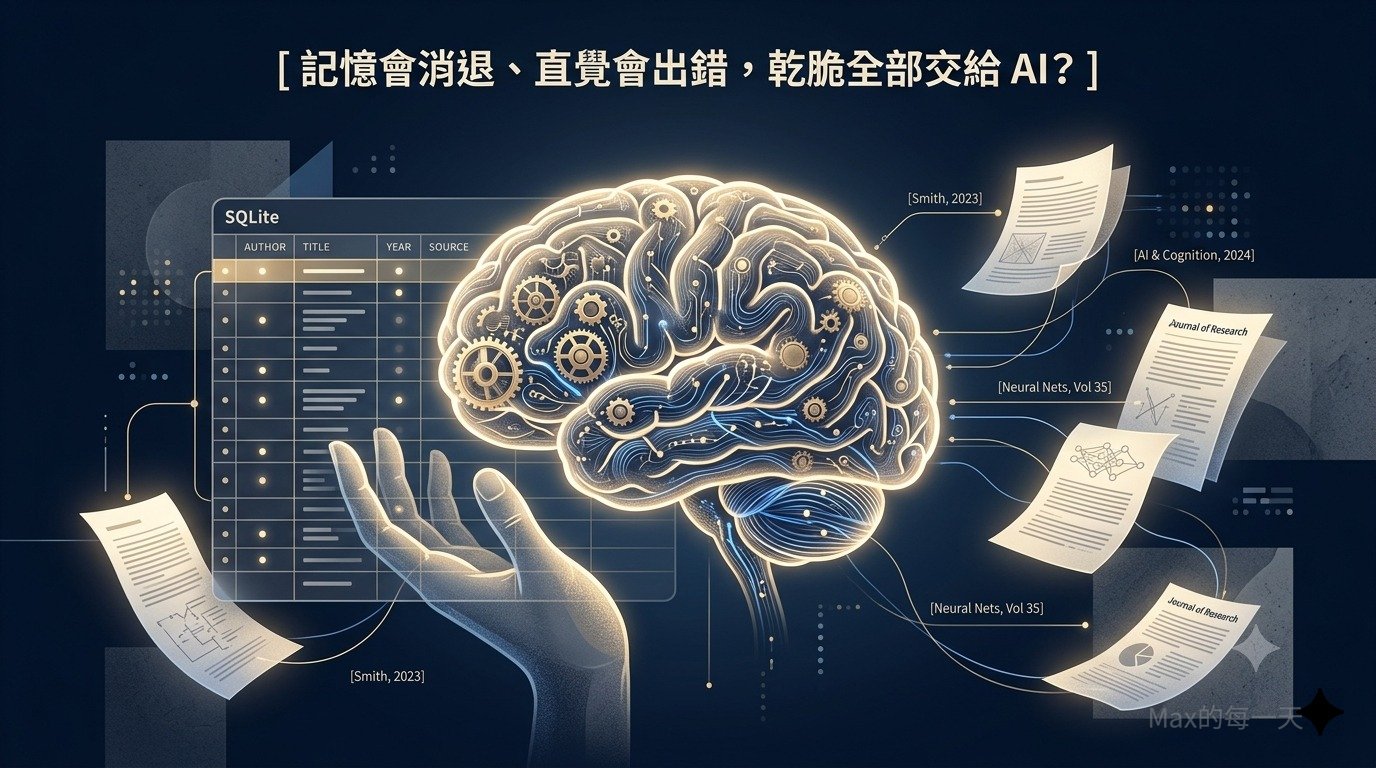
哈爸在 GitHub 上的開源專案:sovereign-research-methodology。它的副標題讓我停下來想了很久:
「當 AI 氾濫、學術語意泡沫化時,我們如何守護思考手感,物理證明『這篇論文是由這套系統物理長出來的』?」
這個問題,我最初的直覺是:有必要嗎?
問題的起點:AI 讓學術界出現了什麼危機?
在生成式 AI 普及之前,「這篇論文是你寫的嗎?」這個問題有個簡單的答案——只要你能答辯,就算是你的。
現在不一樣了。學生可以用 ChatGPT 在一晚上生出一篇有模有樣的論文,引文格式正確、邏輯表面通順、摘要寫得比很多老手還漂亮。但如果你問他:「這篇引用的 Listgarten (2024) 說了什麼,和你的第三章有什麼具體關聯?」——他可能完全答不出來,因為那個引文本來就是 AI 瞎掰的。
這就是這個專案想解決的問題:AI 讓「看起來懂」和「真的懂」之間的距離,縮短到了幾乎無法用外表區分。
這個專案在做什麼?
sovereign-research-methodology 是一套以 SQLite 資料庫為核心的研究方法論系統,由台灣的研究者哈爸(wuulong)開源。
它的核心設計哲學是:不相信語意,只相信物理軌跡。
具體來說,它有幾個關鍵機制:
一、十一表資料庫強制留下痕跡
每一篇引用的論文,必須被「Stage 2 深度消化」——AI 要幫你萃取「十大學術因子」,包括核心問題、獨特貢獻、方法論批判等。這些都被寫入 SQLite 資料庫。如果你只是瞎填一個 cite key 而沒有真正讀過,資料庫會如實反映「這篇文獻從未被消化」。
二、紅軍自審機制(Socratic Grill)
系統會讓 AI 扮演「最刻薄的審稿人」,針對論文的每一個核心主張提出尖銳攻擊,研究者必須親自答辯。攻擊、答辯、裁決,全部寫入 red_team_logs 資料表。只要有任何一筆裁決是「VULNERABLE(脆弱有漏洞)」,系統就會物理鎖定,拒絕讓論文進入最終編譯。
三、一鍵重建與自證
整個大腦資料庫可以被導出為純文字 JSON,任何人都可以下載、重建,驗證這條時序演化軌跡是否真實存在、是否自洽。這就是「物理證明這篇論文從這套系統長出來」的意思。
我提出的第一個挑戰:人會遺忘
理解了這套系統之後,我想到了一個問題:
就算你在寫論文的時候真的理解了,記憶會消退。五年後你還記得嗎?這樣的「思考手感」有什麼長遠意義?
這個問題乍看像是在否定整套方法論——如果人終究會忘,那費這麼大力氣建立「真實理解的物理軌跡」,意義在哪裡?
但仔細想,這個挑戰其實搞錯了目標。
這套系統的目的,不是讓你永遠記住細節,而是確保「寫作當下,你是真的理解了、而不是讓 AI 替你幻想了一個版本」。
資料庫裡的答辯紀錄、摩擦數據、Socratic 問答——這些不是記憶的替代品,而是補償機制。正因為人會忘,才需要把思考的物理軌跡沉澱下來。五年後你可以重新翻出來重燃;別人可以驗證它是否真實;評審可以追問任何一個節點。
而且,「思考手感」有兩種記憶:你可能忘記某個公式的推導細節(陳述性記憶),但「看到一篇新論文就能直覺感覺哪裡不對」這種直覺(程序性記憶),消退速度慢得多——就像你忘了怎麼解數學題,但不會忘記怎麼騎腳踏車。
第二個挑戰:直覺本來就可能是錯的
但我繼續追問:
就算直覺消退慢,直覺本身也可能是錯的。與其相信一個可能出錯的人類直覺,相信 AI 或外部工具不是更可靠?
這個問題更犀利。人類認知偏誤的研究汗牛充棟——我們高估自己、從眾、見鬼。Kahneman 的研究告訴我們,專家直覺在很多領域都是系統性錯誤的。既然如此,「守護思考手感」是不是在守護一個缺陷?
這裡有一個我認為最重要的哲學問題:
「AI 更可靠」,是對誰的標準而言的可靠?
AI 的「可靠性」不是天生的——它是被人類用訓練資料、人工標注、強化學習校準出來的。
你說「相信 AI 的判斷」
= 相信設計 AI 的工程師和標注者的判斷
= 但這些人的判斷被打包進黑盒,你看不到、無法質疑你沒有跳出「相信人類判斷」的循環,只是把判斷的來源變得更不透明、更難被追問。
更根本的問題是:如果你決定「用 AI 取代自己的判斷」,你怎麼知道 AI 是對的?用另一個 AI 評估第一個 AI?那第二個 AI 誰來評估?這條鏈必須在某個地方由人做出最終判斷——否則就是一個封閉的自指循環,正是這個專案批判的「AI 自指幻覺共謀」。
直覺的功能不是「永遠正確」,是「偵測異常的能力」
人的直覺常常錯。但這裡要先修正一個常見的誤解:現代頂尖的 AI 模型(o1、o3、Claude extended thinking 等)其實確實有反思過程——它們會主動懷疑自己的上一步、表達不確定性、在被追問時重新審視前面的論述。說「AI 不知道自己可能錯」,對現在的模型已是過時的說法。
真正的差異,在於反思之後後果歸誰承擔。
一個研究者在答辯中被指出錯誤,他會失眠、會感到愧疚、職涯可能受影響——這些後果真實地落在他身上,驅動他對話結束後繼續追查、持續修正。AI 的「不確定性表達」是訓練出來的輸出行為,對話結束後它沒有狀態,不會繼續擔心,被證明錯了也不會損失什麼。
這就是 Nassim Taleb 所說的 skin in the game——你的判斷錯了,後果會不會落在你身上?這不是在貶低 AI 的反思能力,而是說這兩種「知道自己可能錯」在功能上仍有本質差異:一個連結著真實後果,一個不連結。
最關鍵的差異:誰能被問責?
| 人類直覺 | AI 判斷 | |
|---|---|---|
| 可能錯誤 | ✅ 是 | ✅ 是(且更難偵測) |
| 可以在答辯中被追問 | ✅ 是 | ❌ AI 不會出席口試 |
| 有動機面對真相 | ✅ 有(名譽、責任感) | ❌ 無 |
| 錯誤被指出後能成長 | ✅ 是 | ⚠️ 需要人介入再訓練 |
學術研究的核心,不只是「輸出正確答案」,而是一個人對自己的知識主張負責,接受挑戰,可以被社群檢驗。這個責任主體,AI 無法替代——不是因為 AI 不夠聰明,而是因為 AI 沒有在學術社群中承擔後果的「皮膚」(skin in the game)。
所以,這套方法論的真正意義是什麼?
回到 sovereign-research-methodology 這個專案。
它不是在宣稱「人類直覺永遠對」,也不是在排斥 AI——事實上整套系統大量使用 AI 來執行低階工作。它在做的事情是:
在 AI 大量介入的研究流程中,強制保留幾個不可被 AI 代勞的關鍵節點——讓人類在這些節點上真正存在過、理解過、答辯過,並把這個過程的物理軌跡留下來。
就像一棟建築的結構審查,不是要求每一根螺絲都由人手鎖,而是要求在關鍵的承重節點上,有人真正檢查過、簽名過、負責過。
在 AI 讓「看起來懂」和「真的懂」幾乎無法區分的時代,這套系統用資料庫的外鍵約束、Verdict Lock、摩擦數據,試圖在這兩者之間重新劃出一條可被物理驗證的界線。
三個讓我繼續追問的問題
討論到這裡,又有幾個更實際的挑戰冒出來,我覺得值得一起想。
「AI 不能出席口試」——但可以讓它間接加入嗎?
表格裡有一格寫著「AI 不會出席口試」,但這個說法其實很快就會過時。Zoom 口試本來就可以開著 ChatGPT,未來甚至可能有大學明文允許 AI 輔助答辯。這樣的話,accountability 的防線是否就瓦解了?
我認為不會,但理由需要說得更精確。
口試委員真正在評估的,不只是「答案對不對」,而是你怎麼推理。「這個結果跟你第三章的假設有什麼衝突?你當初為什麼這樣設計?如果重做你會改什麼?」——這些問題要求的是你自己研究歷程的脈絡,AI 就算在旁邊,也無法替你回答你為什麼做了那個決定、那個夜晚你想通了什麼。
更根本的是:一旦允許 AI 進口試,口試評估的對象就從「這個人懂不懂」,變成了「這個人加上 AI 能不能回答」。 這改變的不是 AI 能否出席,而是口試這件事本身還有沒有意義。那是另一個更大的問題。
沒有「口試」的工作,就可以全部交給 AI 嗎?
這個問題問得很好,而且答案是:很大程度上,是的。
這套方法論從來不是說「所有事情都要人親自來」。它自己也明確區分了「可以安全卸載給 AI 的工作」和「必須死守的主權範疇」。問題是這條線畫在哪裡。
一個比較清晰的判斷方式:
| 這件事有沒有…… | 範例 | 適合交給 AI? |
|---|---|---|
| 客觀對錯可自動驗證 | 程式碼、格式轉換、資料清洗 | ✅ 放手做 |
| 結果可測試、不需問責 | 功能實作、重複性任務 | ✅ 放手做 |
| 需要有人為後果負責 | 研究方向、產品要不要做 | ❌ 人不能退場 |
| 涉及對真實的人的影響 | 醫療、法律、教育判斷 | ❌ 人不能退場 |
換句話說:執行層(how to do it)交給 AI,判斷層(whether to do it, why it matters)人不能缺席。 這條線不是「技術 vs 非技術」,而是「後果由誰承擔」。
讀過摘要,算是真正消化了一篇論文嗎?
這個問題直接戳了這套系統的一個現實痛點。
「Stage 2 深度消化」要求對每篇引用的論文,完整萃取十大學術因子:核心問題、獨特貢獻、方法論、限制、與你研究的具體關聯……全部結構化寫入資料庫。光讀摘要,在這套系統裡只算「DTO_SUMMARY」,MCI 指標只給 30% 的權重;略讀全文是 70%;真正的 Stage 2 才是 100%。
但說實話,強制每一篇引用論文都做完整 Stage 2,對大多數研究者來說很難做到,也不一定必要。這套系統的設計也沒有要求 100%——它要求的是你清楚知道自己有多少篇是真正讀過的,有多少篇只是引了個名字。MCI 指標會如實反映你的消化率,讓你無法對自己和導師假裝「我都讀過了」。
這其實是一個很誠實的設計:它不要求完美,但要求透明。
值得關注的幾個開放問題
當然,這套方法論本身也有它的脆弱點。我在研究這個專案時,整理了一些還沒有被完整回答的問題:
- 紅軍如果也是 AI,攻擊強度會不會天然偏軟? 攻擊者和被攻擊者是同一個模型,這是設計上的同質性偏差。
- 十大學術因子由 AI 萃取,不同模型萃取的結果是否一致? 若不一致,建立在上面的品質保證機制就有沙基問題。
- 學術重力公式的權重是怎麼校準的? 目前這些數字看起來是人工設定的,缺乏實證依據。
這些問題,希望能引發更多討論。
結語
回到最初的問題:記憶會消退、直覺會出錯,那為什麼不乾脆全部交給 AI?
因為「全部交給 AI」的那一刻,你就失去了一件更重要的東西:對自己的思想負責的能力。
AI 可以幫你想得更快、更廣、更少出現格式錯誤。但它無法替你出席口試,無法在你的研究被質疑時感到緊張,無法在五年後被追問時重新思考自己當時是否真的想清楚了。
思考手感,不是關於「我永遠是對的」。它是關於「我在這個知識上真實存在過」。
在 AI 氾濫的時代,這個「真實存在過」,正在變得越來越稀有、越來越值錢。
如果你對這個主題感興趣,可以到 sovereign-research-methodology 看看這套系統的完整設計,包括它的十一表資料庫 schema、四大主權 Skill 規格,以及作者用這套方法「自指自證」撰寫出的完整論文手稿。
"我在這個知識上真實存在過",這個感覺超沒用的,可以生出功能正常的成品比自己曾想通和了解過更值得吧。

